2023. 10. 11. 00:10ㆍRun/Etc
컴파일러 기법 vs 인터프리터 기법 vs 하이브리드 기법
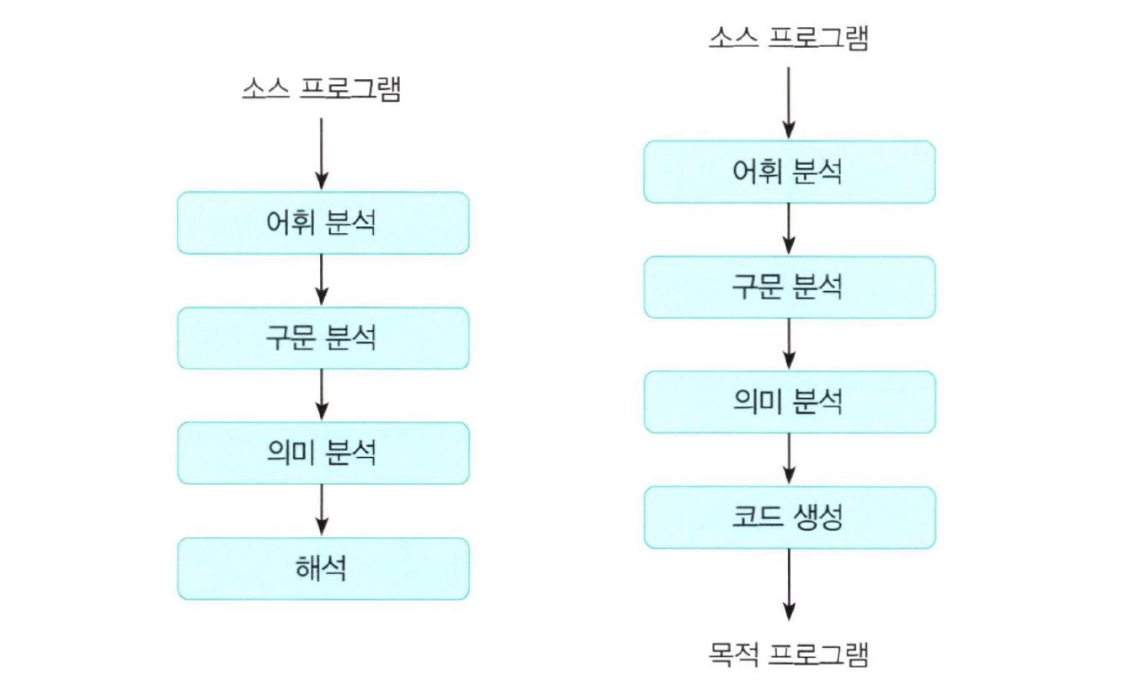
- 컴파일러 기법 (translation)
- 컴파일러: 소스 (고급언어) → 목적언어 (저급언어, 기계어)
- 컴파일러 기법 구성 요소
- 컴파일러
- 어셈블러: 어셈블리어 (저급언어) → 목적언어 (저급언어, 기계어)
- 링커: 각 컴파일된 코드, 라이브러리 하나로 묶어서 로드 모듈로 번역
- 로더: 로드 모듈에서 기계어로 번역, 주 기억장치에 적재
- 프리프로세서: 고급 언어 → 고급 언어
- 전체 파일 스캔하여 한 번에 번역
- 한 번 번역되면 다시 실행할 때 다시 번역할 필요 없음
- 대표 언어: C++, Ada, Fortran, ...
- 인터프리터 기법 (interpretation)
- 인터프리터: 소스 (고급언어) → 다른 기계에서 실행되는 SW로 시뮬레이션
- 한 번에 한 문장씩 (논리적 순서에 따라) 번역
- 다시 실행할 때 다시 번역해야 함
- 대표 언어: JavaScript, Python, LISP, Prolog, ...
- 하이브리드 기법
- 번역 (컴파일러) + 시뮬레이션 (인터프리터)
- 소스 프로그램 → 적당한 번역 과정 → 중간 형태 코드 → 인터프리터 → 결과
- 대표 언어: Java, Perl, ...
수식 AST
- 이항 연산 (Binary)

class Binary extends Expr {
Operator op;
Expr expr1, expr2;
Binary (Operator o, Expr e1, Expr e2) {
op = o;
expr1 = e1;
expr2 = e2;
}
}
- 단항 연산 (Unary)

class Unary extends Expr {
Operator op;
Expr expr;
Unary (Operator o, Expr e) {
op = o;
expr = e;
}
}
- 비교/논리 연산

문장 AST
- 선언문 (Declaration)
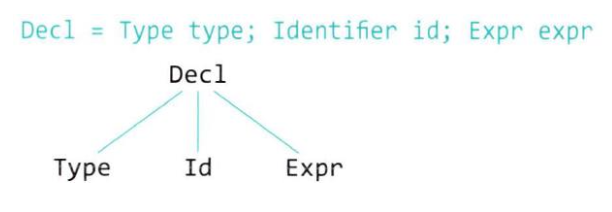
int a = 10;
- 대입문 (Assignment)
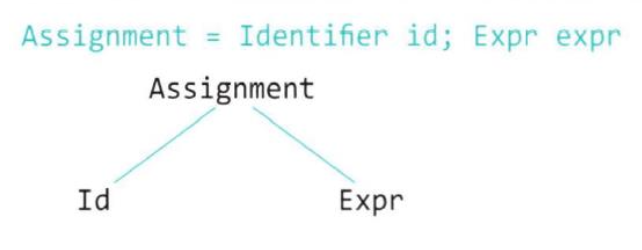
a = 5;
- Print문
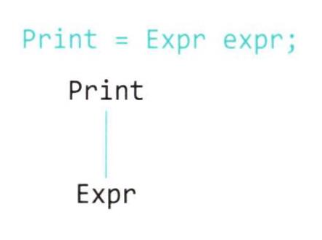
a
- 복합문 (Statements)
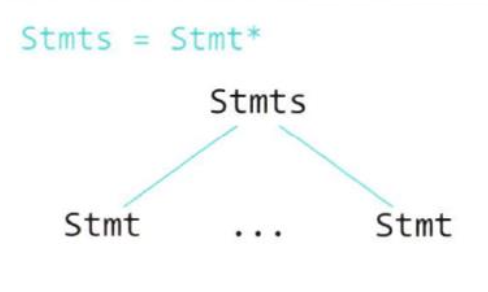
{
x = 0;
x = x + 1;
}
- 조건문 (if)
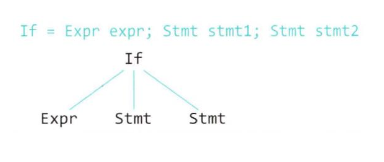
if (a > 0) {
a = a + 1;
}
- while문
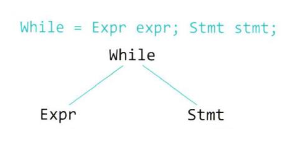
while (a < 0) {
a = a + 1;
}
헷갈리는 기호들
- expression / expr / e = 수식
- ex. 5 + 2 * 3
- identifier / id / i = 식별자
- ex. count,
- statement / stmt = 문장
- ex. a = 10;
- l / letter = 문자
- ex. A, B, ...
- N / number = 수
- ex. 13, 5, ...
- D / digit = 숫자
- ex. 0, 1, ...
- Operator = 연산자
- ex. +, *, ...
Q&A
Q. 프로그래밍 언어의 설계 원칙
A. 효율성, 일반성, 직교성, 획일성, 간결성, 표현력, 확장성, 정확성, 기계독립성, 제약성, 보안성
Q. 프로그램을 주메모리에 적재하는 이유
A. 범용성을 높이기 위해
Q. 프로그래밍 언어의 정의 방법
A. 구문법(syntax) 정의, 의미론(semantics) 정의
Q. 프로그래밍 언어 구현 방법
A.
컴파일러:
- 고급 프로그래밍 언어 → 기계 코드 번역
- 규모가 큰 상업용, 시스템 프로그램 개발 시 사용 (C++, Ada)
인터프리터:
- 번역 수행 X
- 프로그램이 SW 인터프리터에 의해 소스 형태에서 해석되어 실행
- 규모가 작은 시스템 개발 시 사용 (JavaScript, Python)
하이브리드:
- 두 기법의 장점을 활용 (적당한 번역 + 인터프리터)
- Java, Perl
Q. 컴파일러의 전단부보다 후단부에 대한 연구가 더 활발한 이유
A. 전단부는 소스 언어와 관련이 있어서 각 언어마다 하나씩 필요. 후단부는 목적 기계에 의존적이어서 각 목적 기계마다 하나씩 필요.
Q. 컴파일러에서 어휘 분석하는 이유
A. 소스 코드를 정규 문법(regular grammar)에 따라 토큰으로 분류하여 구문 분석기에 전달하기 위해
Q. 토큰 전달 방식
A.
| 토큰 | a | = | b | + | 3 | ; |
| 토큰번호 | 4 | 23 | 4 | 11 | 5 | 20 |
| 토큰값 | a | 0 | b | 0 | 3 | 0 |
→ (4, a) (23, 0) (4, b) (11, 0) (5, 3) (20, 0) 형태로 구문 분석기에 전달
Q. 컴파일러에서 구문 분석하는 이유
A. 어휘 분석기에서 생성한 토큰이 생성 가능한 것인지 판별하고, 파스 트리 생성하여 중간 코드 생성기에 전달하기 위해
Q. Parser(Syntax analyzer) 필요한 이유
A. 소스 프로그램이 하는 것 구문 분석해서 프로그램 문장들의 AST를 계속 생성하고 반환
Q. 컴파일러에서 중간 코드 생성하는 이유
A. 여러 종류의 프로그래밍 언어를 해당 컴퓨터(CPU)의 기계어와 대응시키기 위해
Q. 구문 분석 단계에서 유도(derivation)하는 이유
A. 문장 및 프로그램이 구문법에 맞는지 검사하기 위해 유도 진행
Q. 프로그램은 명령어를 조합해 만듦. 명령애 개수를 유한하게 정의하는 방법은?
A. 점화식, 재귀식(모호성 발생할 수 있으므로 모호성 제거 필요)을 사용
Q. 모호성이란
A. (1) 어떤 스트링에 대해 두 개 이상의 좌측 유도를 갖는 문법 (2) 어떤 스트링에 대해 두 개 이상의 파스 트리 갖는 문법
Q. 모호성 제거 방법
A. (1) 모호한 문법을 모호하지 않은 문법으로 수정 (2) 문법을 모호하지 않게 수정
// 변경 전
E → E + E | E * E | (E) | N
// 변경 후
E → E + T | T
T → T * F | F
F → (E) | N// 변경 전
S → if E then S | if E then S else S
// 변경 후
S → if E then S end | if E then S else S
Q. 최근 언어는 예약어가 많음. 예약어 많을 때 장단점은?
A.
장점: 프로그램을 컴퓨터가 읽기 쉬움, 컴파일러가 symbol table을 빠르게 접근할 수 있음, 오류가 적음
단점: 다 기억하기 어려움, 식별자와 중복될 수도 있음
Q. CSG, CFG, BNF, EBNF?
A.
- CSG(Context-Sensitive Grammar): 문맥유관문법. 특수한 문맥에 의존해서 대체됨
- CFG(Context-Free Grammar): 문맥자유문법. 생성규칙 논터미널 기호 하나로만 구성. CFG 표기법 종류 = BNF, EBNF, 구문 도표, ...
- BNF(Backus-Naur Form): CFG 표기법 중 하나. 생성 규칙들의 집합
- EBNF(Extended BNF): BNF에서 메타 심볼 {} [] (|) 추가된 형태
Q. BNF(EBNF)에서 메타기호를 작은 따옴표 안에 표기하는 이유 (ex. '{')
A. 메타기호가 터미널쪽(오른쪽)에서 사용되면 혼동될 수 있음
Q. LL parsing (top-down) 방식이란
A.
- 루트 노드에서 시작해서 단말 노드 만들어 나감 (Expand)
- 입력 string 한 symbol 씩 왼쪽에서 오른쪽으로 scanning (LR scanning)
- Leftmost derivation(좌측 유도), Left parse 생성
- Backtracking: 유도 진행하다가 틀리면 다음 생성규칙으로 다시 적용 (시간 오래 걸림)
- Left recursion으로 인해 무한 loop 발생할 수 있음
Q. LR parsing (bottom-up) 방식이란
A.
- 단말 노드에서 시작해서 루트 노드를 향해 감 (Reduce)
- 입력 string 한 symbol 씩 왼쪽에서 오른쪽으로 scanning (LR scanning)
- Rightmost derivation(우측 유도), Right parse 생성
- 대부분의 compiler가 해당 방식 사용
- 실제로 정의된 문법으로부터 파싱 테이블 손으로 계산하여 얻기 매우 복잡
- 파싱 스택: 상태 번호, 문법 심벌 교대로 보유
- 입력 버퍼: 파싱을 위해 주어진 입력 string 존재
Q. 상태 전이도(State diagram), 구문 도표(Syntax diagram)란
A.
- 상태 전이도: 어휘 분석 단계에서, 어떤 모양의 토큰을 인식할 수 있는지를 쉽게 파악할 수 있는 그림
- 구문 도표: 도표로 구문을 표현하는 것 (BNF와 대응. CFG 표기법 중 하나)
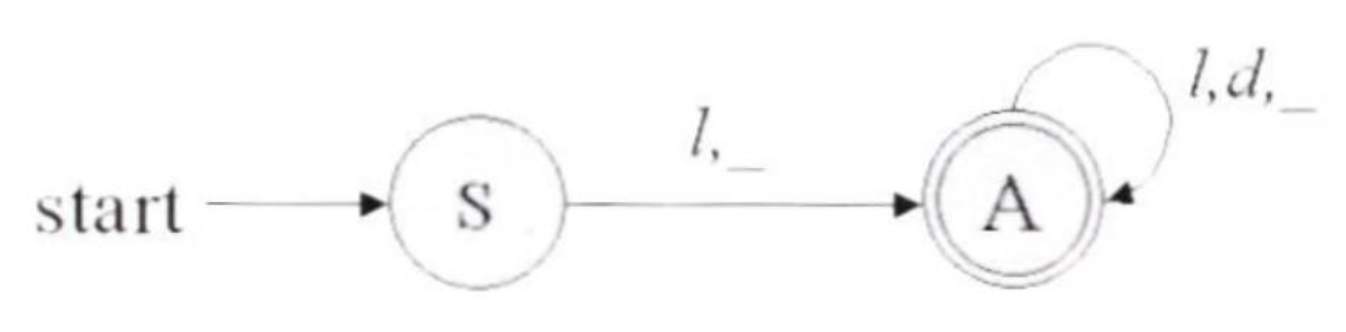
'Run > Etc' 카테고리의 다른 글
| [Etc] LaTeX 기호 모음 (0) | 2023.10.11 |
|---|---|
| [Etc] Render Pipeline Converter 없음 (0) | 2023.10.11 |
| [Etc] Mitsuba Renderer 설치 (0) | 2023.10.11 |
| [Etc] NeRF-pytorch 코드 실행하기 (1) | 2023.10.10 |
| [Etc] LaTeX/Overleaf 사용팁 (0) | 2023.10.10 |