2023. 10. 11. 00:06ㆍRun/Machine Learning
Neural networks
Learn the basics of neural networks and backpropagation, one of the most important algorithms for the modern world.
www.youtube.com
1. Neural Network
신경망에는 다양한 종류가 있음 (CNN, LSTM, ...)
그중에서, 손글씨를 인식하기에 충분한, 가장 기본적인 형태의 신경망에 대해 다뤄볼 것임

28x28 픽셀 → 784개의 뉴런
각 뉴런은 각 픽셀의 밝기를 나타내고(어두움 0.0 ~ 밝음 1.0) 신경망의 입력값(Activation)임
큰 입력값이 주어질수록 신경망이 더 큰 정도로 활성화됨
신경망은 이미 숫자를 인식하도록 train 되어있음

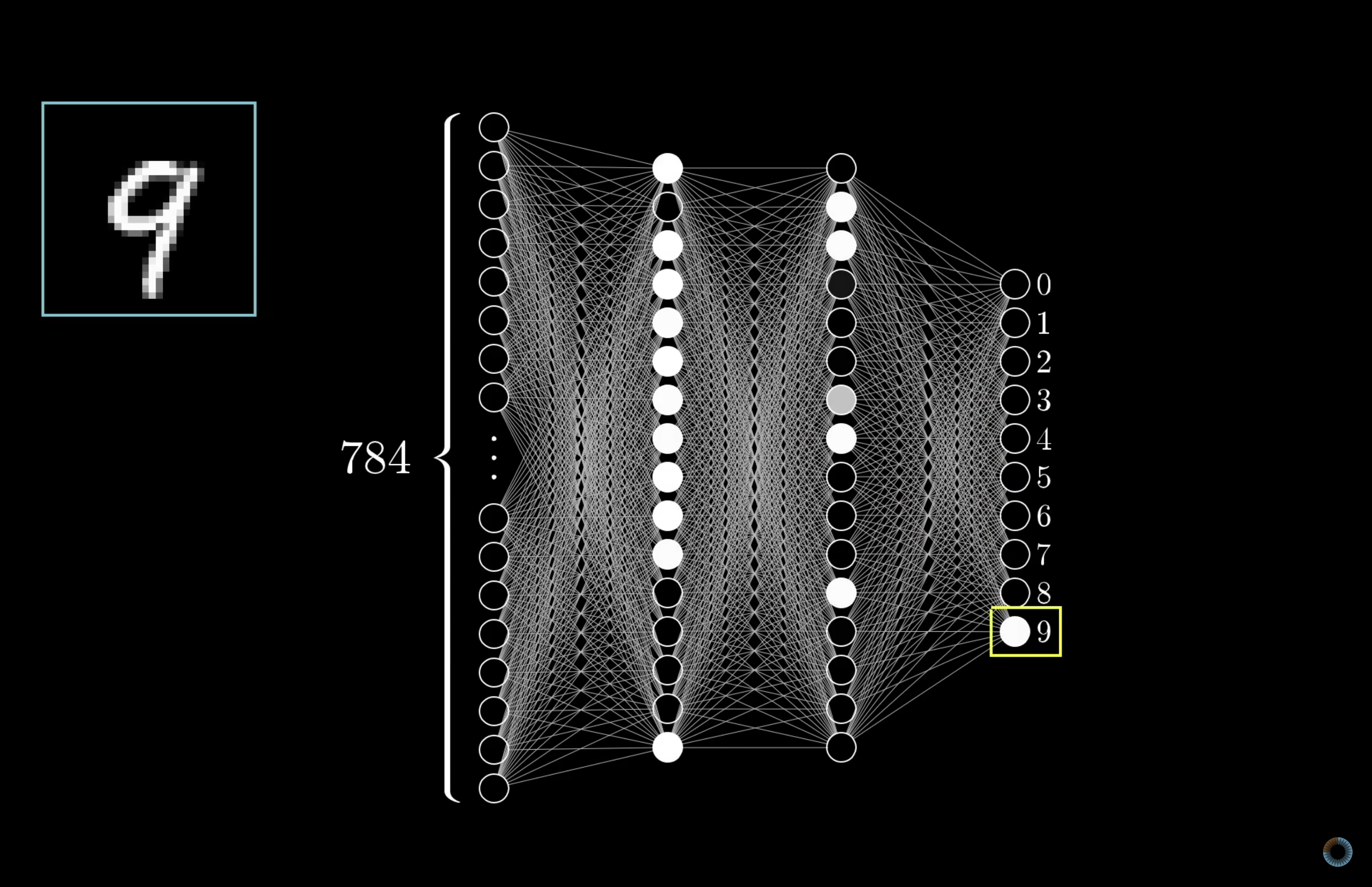
출력층은 총 10개의 뉴런을 가지고 있고, 각 뉴런은 0부터 9까지의 숫자를 대표함
뉴런들은 0과 1 사이의 어떤 값을 가지고, 그 값은 해당 뉴런이 대표하는 숫자와 입력값이 일치하는 정도를 나타냄
(ex. 뉴런 0의 값이 0.7이라면, 70%의 확률로 입력값이 0일 것임을 의미)
입력층과 출력층 사이에는 hidden layer라고 불리는 몇 개의 층들이 있음
신경망은 기본적으로 한 층에서의 활성화가 다음 층의 활성화를 유도하는 방식으로 작동함
Training을 통해 적절한 weight, bias 찾아내는 것이 목표

가중치(weight)를 곱한 픽셀들을 표현하면 위 사진과 같음
ROI를 제외한 픽셀의 가중치를 0에 가깝게 만들고, 각 픽셀에 가중치를 곱한 값의 합(weighted sum)을 구함
이때 값을 0과 1 사이의 값으로 만들기 위해 활성화 함수(sigmoid, ReLU, ...)에 넣음
$\sigma(w_1a_1 + w_2a_2 + ... + w_na_n + bias)$
뉴런의 활성화는 weighted sum이 얼마나 큰지에 따라 정해져있음
이때 특정 값 이상에서만 활성화되도록 하기 위해, sigmoid 함수에 넣기 전에 가중치의 합에 bias를 더할 수 있음
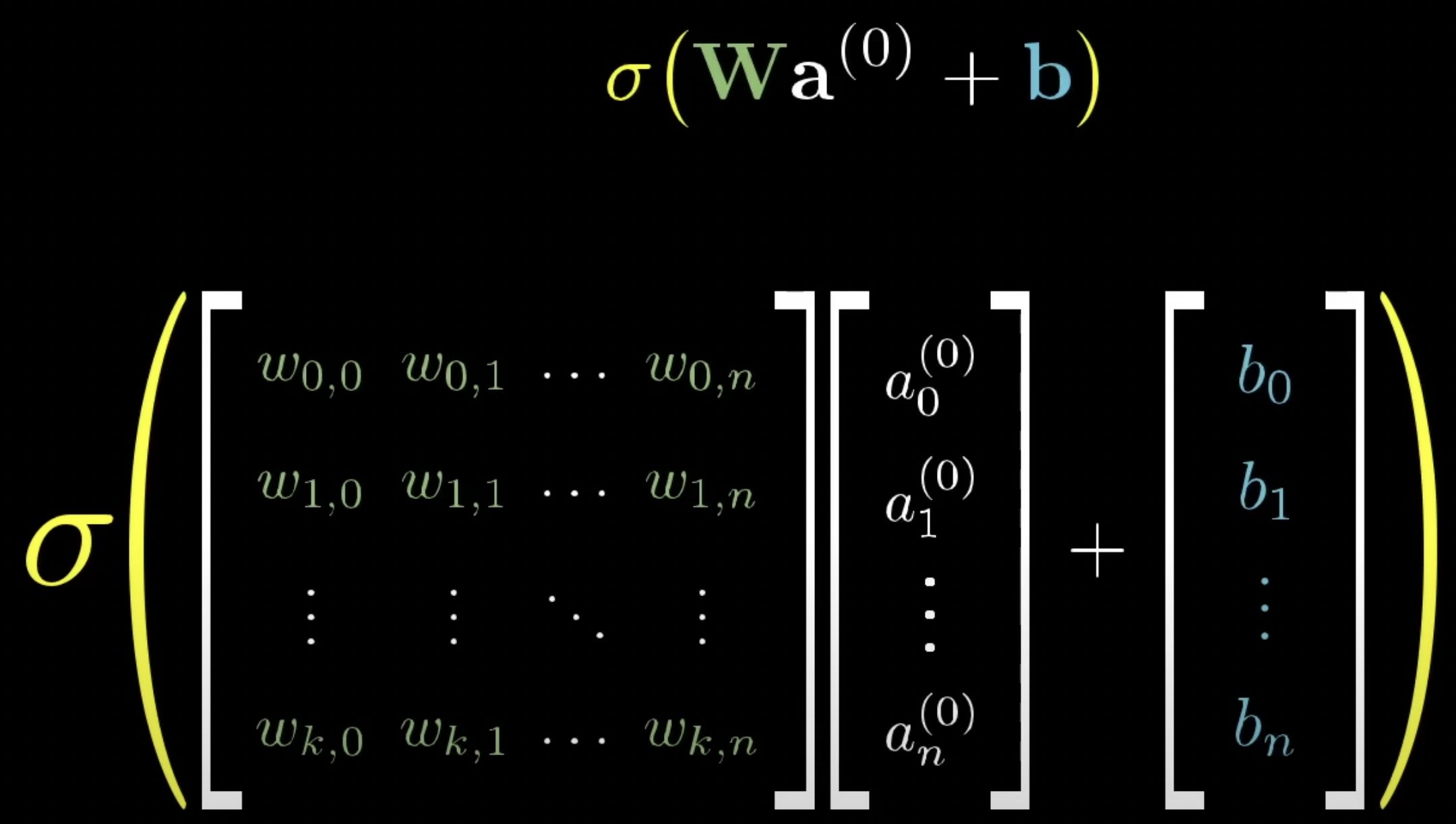
여태껏 하나의 뉴런에 대해서 설명함. 즉, 모든 뉴런에 대해 이와 같은 작업을 진행함
따라서 이 신경망은 총 약 13,000개의 weight와 bias를 가지게 됨
2. Gradient Descent, how neural networks learn
신경망은 어떻게 적절한 weight와 bias를 찾을까?
신경망은 학습 데이터(ex. MNIST dataset)를 통해 weight, bias를 조정해가며 성능을 개선함
데이터에는 손으로 쓰인 숫자들과, 그 숫자가 무슨 숫자인지를 나타내는 라벨이 포함됨
최종적으로는 학습 데이터를 넘어서 일반적인 이미지들도 잘 인식하는 것이 목표
Test는 신경망을 학습시킨 후 이전에 보여주지 않은 데이터를 보여주어 얼마나 잘 분류하는지를 보는 것

Weight, Bias는 맨처음에 랜덤한 초기값을 가짐
Cost function을 통해, 신경망의 출력값과 실제 정답값의 차의 제곱을 모두 더함
Cost function은 약 13,000개의 weight, bias를 입력받아 이 값들이 얼마나 적절한지를 나타내는 하나의 값을 출력함
어떻게 weight, bias를 어떻게 바꿔야 더 나아질지 알려줄까? 즉, cost 값이 가장 작은 경우를 어떻게 찾을까?
→ Gradient Descent
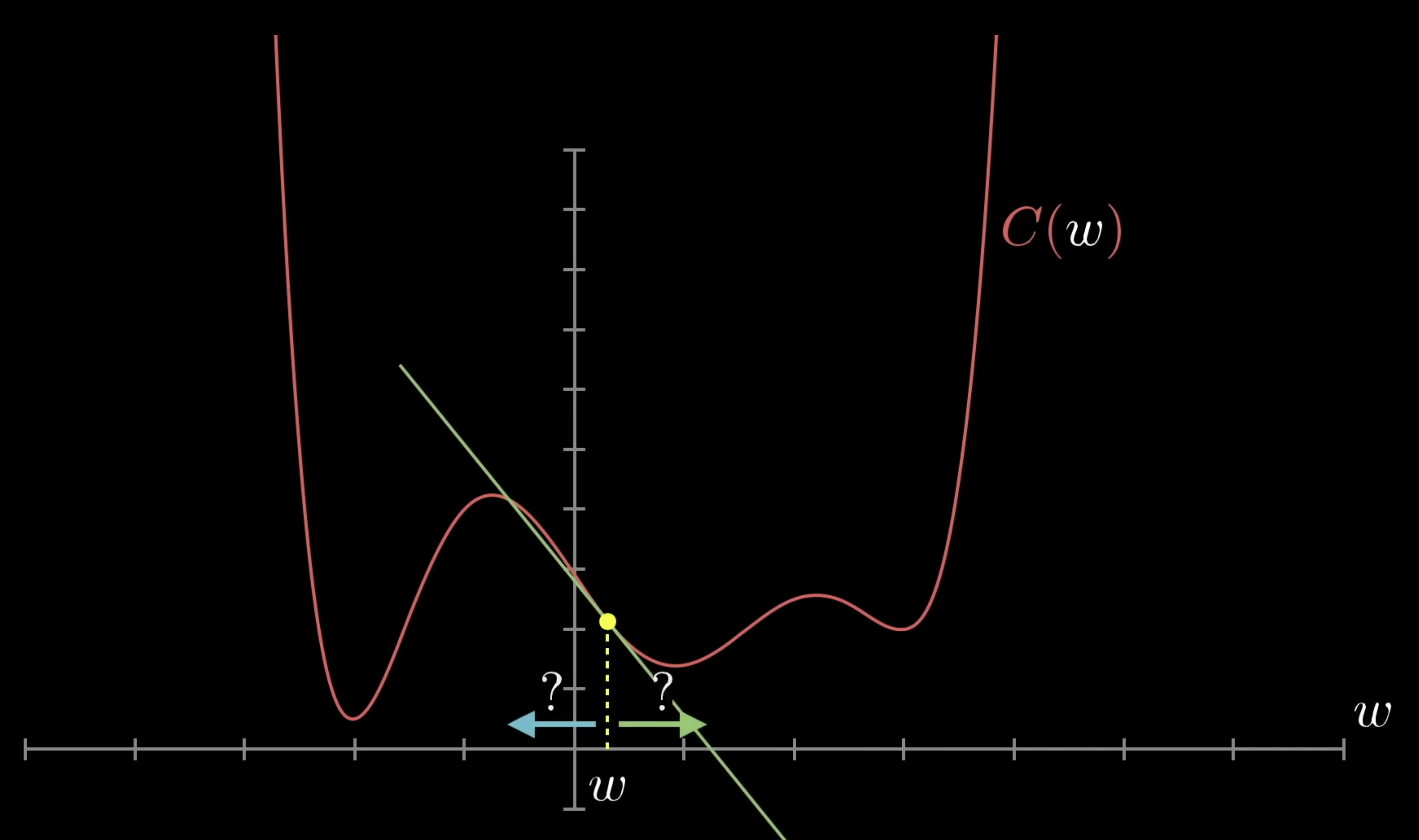
기울기가 양수면 왼쪽으로 이동하고, 기울기가 음수면 오른쪽으로 이동함
적절한 방향으로 이동하면 cost function의 local minimum에 도달함
Local minimum이 함수에서 가장 작은 출력값이라는 보장은 없음
Gradient descent를 통해 local minimum을 찾으려면 cost function이 continuous해야 함
한 번에 이동할 거리(step size)를 기울기에 비례해서 설정하면,
기울기가 줄어들수록 이동하는 거리가 점점 작아지고, 이는 over shooting을 막을 수 있음

약 13,000개의 weight, bias를 거대한 column vector로 만들었다고 가정해보자
Cost function의 gradient의 음의 방향 ($-\nabla C(\vec{W})$) 역시 벡터가 됨
이 벡터는 어떤 방향이 cost function을 가장 빠르게 감소시켜 주는지를 알려줌
이를 통해 weight, bias를 조정할 수 있음
Gradient 계산을 효과적으로 만드는 알고리즘이 신경망이 얼마나 효과적으로 학습할 수 있는지를 결정하는 핵심 요소임
→ Backpropagation


$-\nabla C(\vec{W})$의 각 요소들은 우리에게 2가지를 알려줌
1) 이동해야 하는 방향 (왼쪽? 오른쪽?)
2) 어떤 요소를 조정하는 것이 더 큰 영향을 미치는가
어떤 한 weight를 조정하는 것이 다른 weight를 조정하는 것보다 cost function에 더 큰 영향을 미칠 수 있음
따라서 $-\nabla C(\vec{W})$는 각 weight와 bias의 중요도를 나타냄
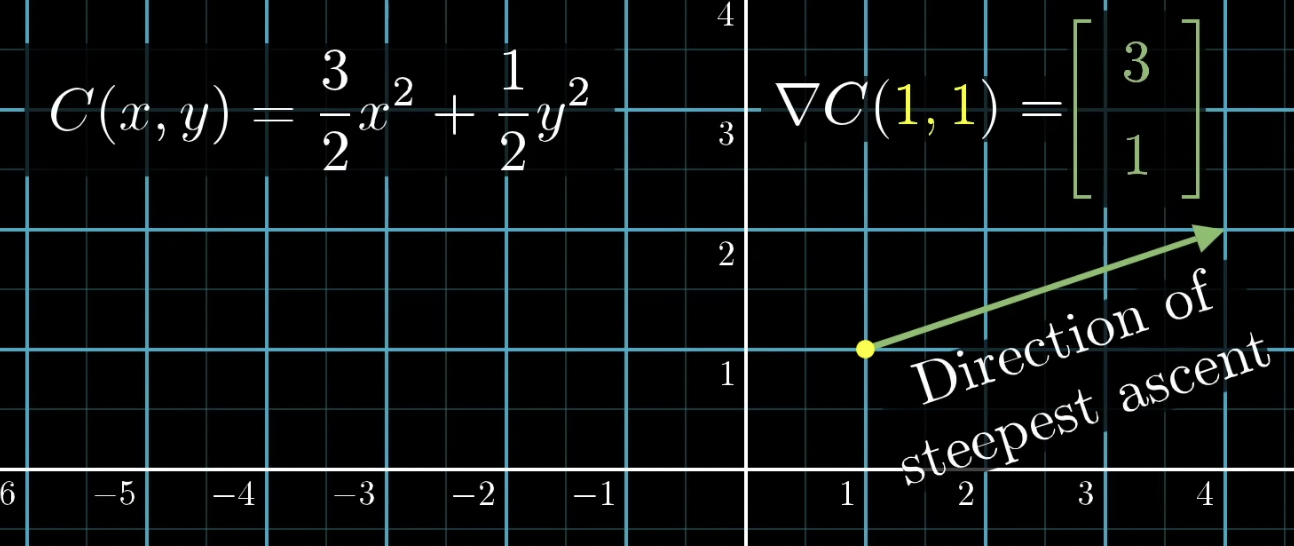
위 예시에서, 점 (1, 1) 부근에서 x를 조정하는 것이 y를 조정하는 것보다 3배 더 영향이 크다는 것을 알 수 있음

지금껏 다룬 신경망은 숫자 이미지를 아주 잘 인식하더라도, 직접 숫자 이미지를 그려내지는 못 함
즉, 0~9 중 어느 것도 아닌 이상한 이미지를 주더라도, 특정 숫자로 예측을 함
현재는 이보다 발전된 여러 신경망들이 개발되고 있음
3. Backpropagation
Backpropagation은 복잡한 gradient를 계산하기 위한 알고리즘
출력층의 특정 뉴런의 값을 변경시킬 수 있는 방법에는 3가지가 있음
1) Increase $b$
2) Increase $w_i$ (in proportion to $a_i$)
앞의 레이어에서 가장 밝은 뉴런과의 연결이 가장 큰 효과를 냄
이 뉴런의 weight를 높이는 것이, 다른 뉴런의 weight를 높이는 것보다 cost function에 더 큰 영향을 줌
3) Change $a_i$ (in proportion to $w_i$)
이전 계층의 모든 활성화를 변경하는 것
즉, 특정 뉴런과 연결된 뉴런 중 양의 weight를 가지면 더 밝게, 음의 weight를 가지면 더 어둡게 한다면 해당 뉴런이 더 활성화됨
이 방식을 출력층의 0~9 뉴런에 대해 모두 진행하며, 각 층에 대해 역으로 진행함
이 과정은 매우 오랜 시간을 필요로 함
그래서 대신 Stochastic Gradient Descent 방법을 일반적으로 사용함
학습 데이터를 무작위로 섞은 후 이를 mini-batches로 나눔
그런 다음 mini batch에 따라 gradient descent을 계산함 (≠ cost function의 gradient)
각 mini batch는 꽤 좋은 근사값을 제공하지만, 무엇보다 일반 gradient descent 보다 빠름
4. Backpropagation Calculus

위 신경망의 한 학습 예제에 대한 cost는 $C_0(...) = (a^{(L)} - y)^2$ 즉, $(0.66 - 1.00)^2$ 임
$w^{(L)}$의 작은 변화에 cost function이 얼마나 민감하게 반응하는가, 즉, $C$의 $w^{(L)}$에 대한 미분값이 무엇인가
$\partial w^{(L)}$ 는 $w^{(L)}$에 가해진 변화값, $\partial C$ 는 그 결과로 cost가 바뀌는 정도
우리가 알고자 하는 것은 그 비율임 $\partial C / \partial w^{(L)}$

$w^{(L)}$의 변화로 $z^{(L)}$이 변하고, 이에 의해 $a^{(L)}$이 변하고, 이에 의해 $C_0$이 변함
따라서 아래와 같이 표현할 수 있음

이것이 chain rule 임
세 비율을 곱하는 것으로 $C$의 $w^{(L)}$의 변화에 대한 민감도를 알 수 있는 것
마지막 도함수를 통해 weight에 생긴 변화가 마지막 층에 미치는 영향은 이전 층의 활성화 정도에 따라 달린 것을 알 수 있음 ($2(a^{(L)} - y)$)
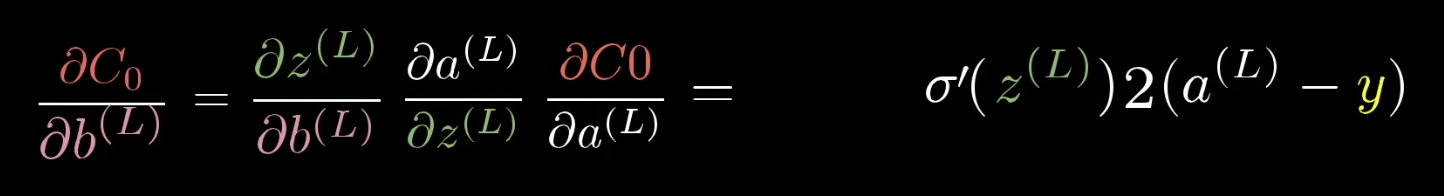
위의 식을 통해 cost function이 이전 층의 활성화 정도에 얼마나 민감한지 알 수 있음
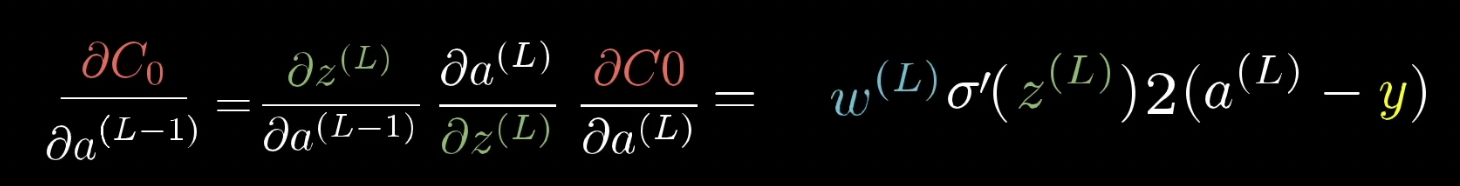
이처럼 활성화 정도에 직접적으로 영향은 줄 수 없더라도, chain rule을 통해 거꾸로 나아가며 이전 weight, bias에 얼마나 민감한지 알 수 있음


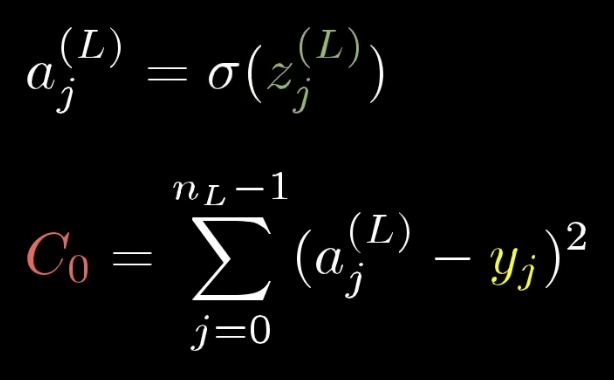


좀 더 복잡한 구조의 신경망의 경우 위와 같음
[정리]
Cost function의 gradient를 구할 때 bias로 미분할 수 있고, weight로 미분할 수 있고, 활성화 값으로도 미분할 수 있음
Backpropagation은 신경망의 출력값과 실제 정답값 간의 오차를 계산하고,
이 오차를 역방향으로 각 레이어에서의 weight, bias에 대한 미분을 계산하여 gradient를 얻는 알고리즘임
Chain rule로 gradient($\nabla C$)의 각 구성 요소를 결정하는 도함수를 구할 수 있음
Backpropagation을 사용하여 각 레이어의 weight, bias에 대한 gradient를 계산하고,
이 gradient를 gradient descent을 통해 weight, bias를 업데이트함
이를 반복하여 cost function의 local minimal을 찾음
'Run > Machine Learning' 카테고리의 다른 글
| [Machine Learning] CS231N #6 Training Neural Networks 1 (0) | 2023.10.17 |
|---|---|
| [Machine Learning] CS231N #5 Convolutional Neural Networks (0) | 2023.10.16 |
| [Machine Learning] CS231N #4 Backpropagation and Neural Networks (0) | 2023.10.15 |
| [Machine Learning] CS231N #3 Loss Functions and Optimization (0) | 2023.10.14 |
| [Machine Learning] CS231N #2 Image Classification (0) | 2023.10.12 |