[Computer Vision] 머신러닝 & OpenCV #1 머신러닝 개요, KNN
2023. 10. 11. 00:07ㆍRun/Computer Vision
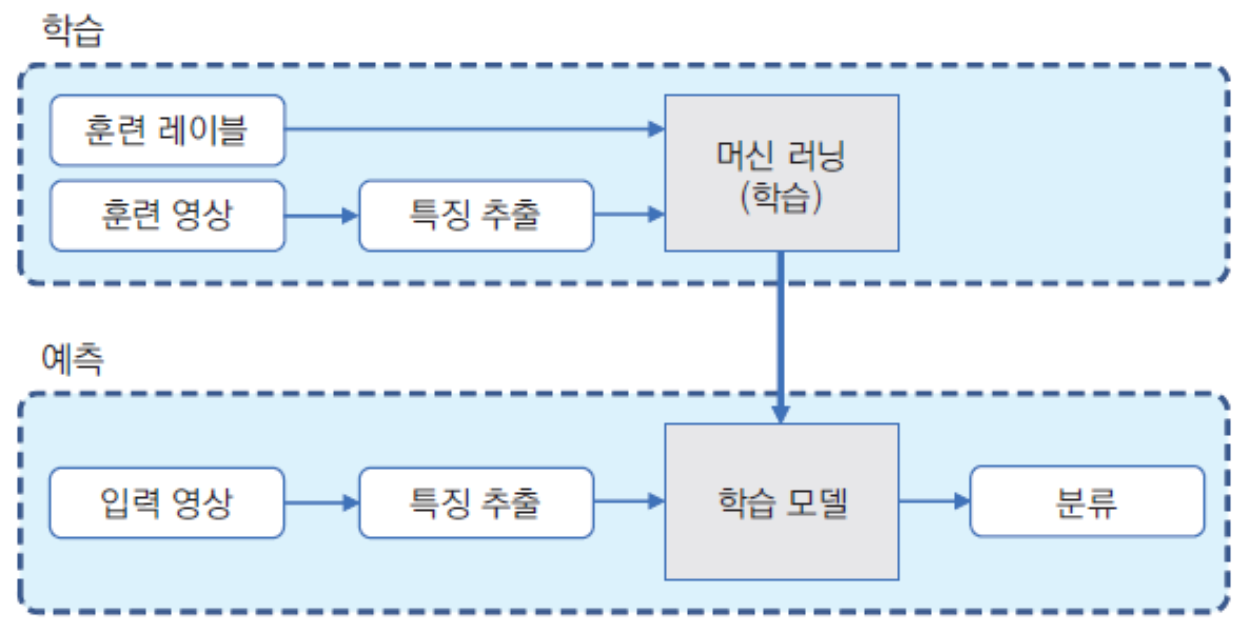
1. 머신러닝
- 주어진 데이터를 분석하여 규칙성, 패턴 등 찾고 이를 통해 의미있는 정보 추출하는 과정
- 학습(train): 데이터(or feature)로부터 규칙 찾아내는 과정
- 모델(model): 학습에 의해 결정된 규칙
- 예측(predict)/추론(inference): 새 데이터를 학습된 모델에 입력으로 넣고 결과를 판단하는 과정
- 딥러닝 = 머신러닝의 한 종류
- 머신러닝: 지도학습(supervised learning), 비지도학습(unsupervised learning), 강화학습(reinforcement learning)
- 지도학습: 정답(label) 알고 있는 데이터 이용하여 학습 진행. 가장 많이 사용.
- 영상의 픽셀 값은 조명 변화, 객체 이동 등에 의해 민감하게 변하기 때문에 픽셀 값을 그대로 머신러닝 입력으로 사용하지 않음
- 대신 영상의 변환에도 크게 변하지 않는 특징 정보(feature vector) 추출하여 머신러닝 입력으로 사용
- 지도학습에서는 다수의 훈련 영상에서 feature vector 추출하고 이를 통해 머신러닝 알고리즘을 학습시켜 모델을 구함
- 추론 과정에서도 입력 영상으로부터 feature vector 추출하고 모델에 입력해 결과 얻을 수 있음
- 회귀(regression): 연속된 수치 값 예측하는 작업 (ex. 키 주어졌을 때 몸무게 예측)
- 분류(classification): 이산적인 값 결과로 출력하는 작업 (ex. 사과 or 바나나)
- 비지도학습: 훈련 데이터의 정답에 대한 정보 없이 오로지 데이터 자체만을 이용하여 학습 진행.
- 여러 집합에서 서로 구분되는 특징 이용하여 서로 분리하는 작업
- 군집화(clustering)

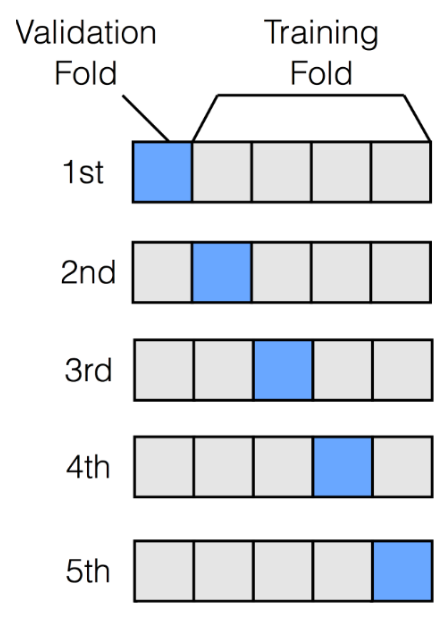
- K-fold cross-validation
- 5개로 나눠서, 4개로 훈련, 나머지로 성능 측정, ... 한 사이클 반복
- 결과에 따라 learning rate 수정, 다시 한 사이클 반복, ... → 최적의 learning rate 찾아나가기
- Test set으로 성능 측정하면 파라미터가 test set에 최적화됨, 하지만 우리가 원하는 것은 실제로 사용할 데이터에 최적인 파라미터, 그래서 validation set 따로 둠
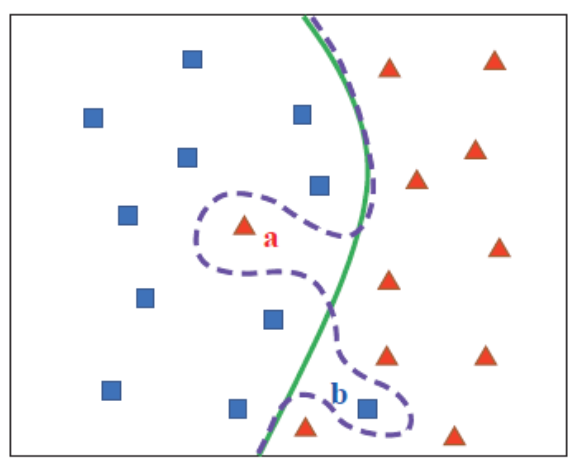
- 일반적으로 훈련 데이터에는 오류(잡음 or 이상치)가 있음
- (1) 데이터에 잡음 없도록 하기 (2) 모델이 잡음에 대응할 수 있게 하기 → (1)이 우선
- 두 종류를 완벽히 구분하는 경계면은 새 입력 데이터에 대해 오히려 정확도 떨어질 수 있음(overfitting), 적당한 경계면이 필요
2. OpenCV 머신러닝 클래스
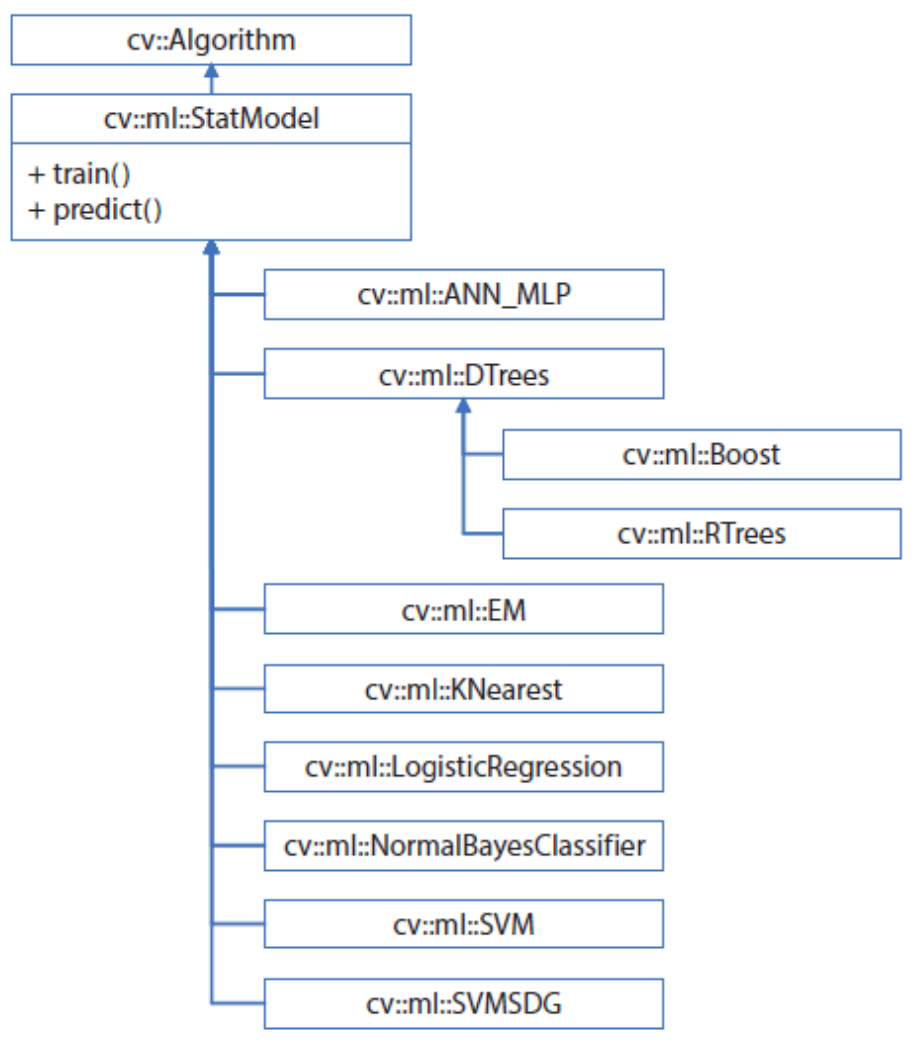
- OpenCV에서 제공하는 머신러닝 클래스는 주로 ml 모듈에 포함
- cv::ml::StatModel 추상 클래스 상속받아 만들어짐
- StatModel::train(): 머신러닝 알고리즘 학습시키는 멤버 함수 (가상함수로 선언됨)
- StatModel::predict(): 테스트 데이터에 대한 결과 예측하는 멤버 함수 (가상함수로 선언됨)
- 몇몇 클래스는 자신만의 학습, 예측을 위한 멤버 함수 따로 제공하기도 함 (직접 오버로딩하여 사용)
- virtual bool StatModel::train(InputArray samples, int layout, InputArray responses)
- 가상함수로 선언됨
- 각 머신러닝 알고리즘은 각자에 맞는 방식으로 train() 재정의 (필수는 아니지만 보통 그렇게 함)
- StatModel 클래스 상속받은 클래스 객체에서 train() 호출
- layout
- ROW_SAMPLE: 각 훈련 데이터가 samples 행렬에 row 단위로 저장
- COL_SAMPLE: 각 훈련 데이터가 samples 행렬에 col 단위로 저장
- virtual float StatModel::predict(InputArray samples, OutputArray results = noArray(), int flags = 0) const;
- 순수가상함수로 선언됨
- 각 머신러닝 알고리즘은 각자에 맞는 방식으로 predict() 재정의
- 일부 머신러닝 알고리즘 구현 클래스는 predict() 대신할 수 있는 고유의 예측 함수 제공
| ANN_MLP | 인공신경망(artificial neural network) 다층 퍼셉트론(multi-layer perceptrons) 여러 개의 은닉층을 포함한 신경망 학습시킬 수 있고, 입력 데이터에 대한 결과 예측할 수 있음 |
| DTrees | 이진 의사 결정 트리 (decision tree) 알고리즘 Boost 클래스(부스팅 알고리즘), RTree 클래스(랜덤 트리 알고리즘)의 부모 클래스 |
| Boost | 다수의 약한 분류기(weak classifier)에 적절한 가중치 부여하여 성능 좋은 분류기 만듦 |
| RTrees | 입력 feature vector를 다수의 트리로 예측하고 결과 취합하여 분류 or 회귀 수행 |
| EM | 기댓값 최대화(expectation maximization) 가우시안 혼합 모델 이용한 군집화 알고리즘 |
| KNearest | KNN 알고리즘 |
| LogisticRegression | 로지스틱 회귀 이진 분류 알고리즘의 일종 |
| NormalBayesClassifier | 정규 베이즈 분류기 각 클래스의 feature vector가 정규 분포 따른다고 가정, 전체 데이터 분포 가우시안 혼합 모델로 표현 학습 데이터로부터 각 클래스의 평균 벡터와 공분산 행렬 계산, 이를 예측에 사용 |
| SVM | Support Vector Machine 두 클래스의 데이터를 가장 여유있게 분리하는 초평면 구함 |
| SVMSGD | Stochastic gradient descent SVM SGD를 SVM에 적용하여 대용량 데이터에 대해서도 빠른 학습 가능 |
3. KNN (K-Nearest Neighbor)
- 분류 또는 회귀에 사용되는 지도학습 알고리즘
- 분류에 사용할 경우
- 특정 공간에서 테스트 데이터와 가장 가까운 k개의 훈련 데이터 찾음
- k개의 훈련 데이터 중 가장 많은 클래스를 테스트 데이터의 클래스로 지정
- 회귀에 사용할 경우
- 테스트 데이터와 인접한 k개의 훈련 데이터의 평균을 테스트 데이터의 값으로 지정
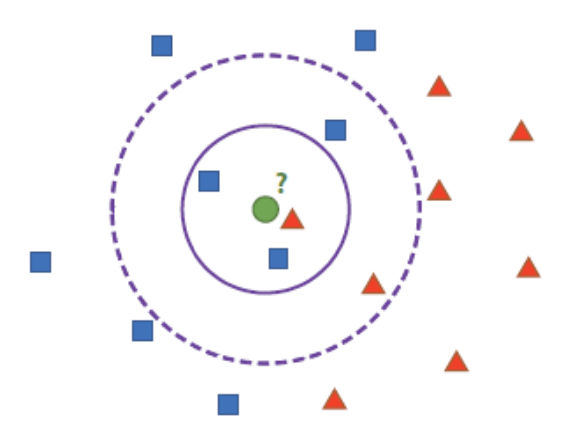
- 위 예제에서 녹색 점과 가장 가까운 것은 빨간색이지만, 지정한 범주(k) 내에 가장 많은 것은 파란색
- 보통 k는 1보다 큰 값으로 설정 (1로 설정하면 NN 알고리즘)
- 최적의 k 값을 찾아 설정해야 함 (분포가 아주 균일하면 k가 굳이 클 필요 없음)
- OpenCV KNearest 클래스 사용하기
- ml 모듈에 포함되어 있고 cv::ml 네임스페이스에 정의되어 있음
- KNearest::create(): 정적 멤버 함수 사용하여 KNearest 객체 생성
- KNearest::setDefaultK(): k 값 변경 가능 (default 10)
- StatModel::predict(): k 값 만큼의 최근접 이웃 데이터 찾음
- KNearest::findNearest(InputArray samples, int k, OutputArray results, OutputArray neighborResponses = noArray(), OutputArray dist = noArray()) const;
- 사용 시 함수 인자로 k 값 명시적 지정 가능, predict()보다 더 자주 사용
- 입력 samples 행렬의 각 row에 저장된 테스트 데이터와 가장 가까운 k개의 훈련 데이터 찾아 results 행렬에 저장, 반환
- samples 행렬 row 수 = results 행렬 row 수, col 수 항상 1
- KNearest::setIsClassifier(): 기본적으로 분류에 쓰이지만, 회귀에 적용하려는 경우 false 지정하여 호출
- StatModel::train(): 객체 생성하고 속성 설정한 후 학습 진행
- Lazy training: 실질적으로 학습하는 건 아님, 훈련 데이터와 레이블 데이터를 KNearest 클래스 멤버 변수에 저장
✅ 2차원 점 분류
#include <iostream>
#include "opencv2/opencv.hpp"
using namespace std;
using namespace cv;
using namespace cv::ml;
Mat img;
Mat train, label;
Ptr<KNearest> knn;
int k_value = 1; // k 값 설정
void addPoint(const Point& pt, int cls);
void trainAndDisplay();
int main() {
img = Mat::zeros(Size(500, 500), CV_8UC3); // 0으로 초기화
knn = KNearest::create(); // KNearest 객체 생성
namedWindow("knn");
const int NUM = 30;
Mat rn(NUM, 2, CV_32SC1); // 30x2 랜덤 integer mat 생성
/*
훈련 데이터 (150, 150), (350, 150), (250, 400)을 중심으로 하는 가우시안 분포의 R, G, B점 30개씩 생성
(0, 0) ~ (499, 499) 좌표 사이 모든 점에 대해 kNN 분류 수행하여 R, G, B 색상으로 나타냄
*/
randn(rn, 0, 50); // 평균 0, 표준편차 50 분포 rn에 출력
for (int i = 0; i < NUM; i++) {
addPoint(Point(rn.at<int>(i, 0) + 150, rn.at<int>(i, 1) + 150), 0); // (150, 150) 중심, 클래스 0
}
randn(rn, 0, 50); // 평균 0, 표준편차 50 분포 rn에 출력
for (int i = 0; i < NUM; i++) {
addPoint(Point(rn.at<int>(i, 0) + 350, rn.at<int>(i, 1) + 150), 1); // (350, 150) 중심, 클래스 1
}
randn(rn, 0, 70); // 평균 0, 표준편차 70 분포 rn에 출력
for (int i = 0; i < NUM; i++) {
addPoint(Point(rn.at<int>(i, 0) + 250, rn.at<int>(i, 1) + 400), 2); // (250, 400) 중심, 클래스 2
}
trainAndDisplay();
waitKey(0);
return 0;
}
// 데이터, 레이블 받고 훈련 데이터(좌표), 레이블 데이터(0/1/2) 생성
void addPoint(const Point& pt, int cls) {
Mat new_sample = (Mat_<float>(1, 2) << pt.x, pt.y);
train.push_back(new_sample);
Mat new_label = (Mat_<int>(1, 1) << cls);
label.push_back(new_label);
}
void trainAndDisplay() {
/* Train */
knn->train(train, ROW_SAMPLE, label); // samples, layout, responses
// img의 매 pixel마다 nearest neighbor 찾고 label에 따라 R, G, B 색칠
for (int i = 0; i < img.rows; ++i) {
for (int j = 0; j < img.cols; ++j) {
Mat sample = (Mat_<float>(1, 2) << j, i); // 각 pixel
Mat res;
knn->findNearest(sample, k_value, res); // samples, k, results
int response = cvRound(res.at<float>(0, 0)); // float -> int
// 배경 색칠
if (response == 0) {
img.at<Vec3b>(i, j) = Vec3b(128, 128, 255); // R
}
else if (response == 1) {
img.at<Vec3b>(i, j) = Vec3b(128, 255, 128); // G
}
else if (response == 2) {
img.at<Vec3b>(i, j) = Vec3b(255, 128, 128); // B
}
}
}
/* Display */
for (int i = 0; i < train.rows; i++) {
int x = cvRound(train.at<float>(i, 0)); // float -> int
int y = cvRound(train.at<float>(i, 1)); // float -> int
int l = label.at<int>(i, 0);
// 훈련 데이터 점 색칠
if (l == 0) {
circle(img, Point(x, y), 5, Scalar(0, 0, 128), -1, LINE_AA);
}
else if (l == 1) {
circle(img, Point(x, y), 5, Scalar(0, 128, 0), -1, LINE_AA);
}
else if (l == 2) {
circle(img, Point(x, y), 5, Scalar(128, 0, 0), -1, LINE_AA);
}
}
imshow("knn", img);
}
- 빨간색 영역에 가까운 초록색 점, 초록색 영역에 가까운 파란색 점 때문에 볼록하게 튀어나온 부분 생김
- k 값을 늘리면 다소 완만한 형태로 변함
✅ 필기체 숫자 인식

- OpenCV에서 5000개(0~9까지 500장씩)의 필기체 숫자 영상 제공함
- 이미지 크기: 2000 x 1000 / 각 숫자 크기: 20 x 20 / 각 숫자 개수: 100 x 5 → 각 숫자 영상 잘라내서 훈련 데이터 생성
- 영상들이 이미 어느 정도 정제되어 있으므로 따로 feature vector 추출하지 않고 그대로 사용
- 테스트 데이터 따로 나누지 않고 다 훈련 데이터로 사용
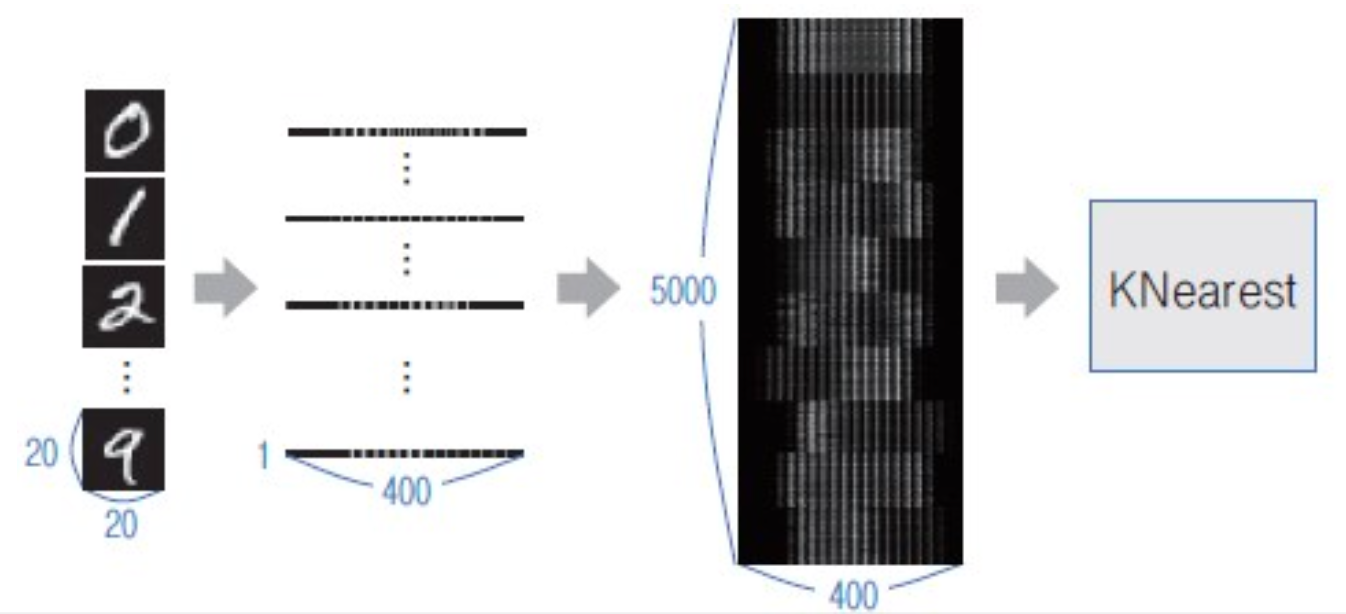
- 숫자 영상 한 장: 20 x 20 → 1 x 400 변환
- 모든 영상 세로로 쌓으면 전체 5000 x 400 행렬, 이를 KNearest 클래스 훈련 데이터로 전달
- 이때 각 필기체 숫자 영상이 나타내는 숫자 값을 레이블 데이터로 전달
- 레이블 행렬의 row 크기 = 훈련 데이터 영상 개수, col 크기 = 1 → 5000 x 1
#include <iostream>
#include "opencv2/opencv.hpp"
using namespace std;
using namespace cv;
using namespace cv::ml;
Point ptPrev(-1, -1);
Ptr<KNearest> train_knn();
void on_mouse(int event, int x, int y, int flags, void* userdata);
int main() {
Ptr<KNearest> knn = train_knn(); // 훈련 함수 호출
if (knn.empty()) {
cerr << "Training failed!" << endl;
return -1;
}
Mat img = Mat::zeros(400, 400, CV_8U); // 400x400 Canvas
imshow("img", img);
setMouseCallback("img", on_mouse, (void*)&img); // 마우스 콜백 함수 등록 (on_mouse 불릴 때마다 img 인자로)
while (true) {
int c = waitKey(0);
// ESC 누르면 종료
if (c == 27) break;
// Space 누르면 글씨 인식, 결과 출력
else if (c == ' ') {
/* 테스트 데이터 가공 */
Mat img_resize, img_float, img_flatten, res;
resize(img, img_resize, Size(20, 20), 0, 0, INTER_AREA); // 400x400 -> 20x20 (훈련 데이터와 같도록)
img_resize.convertTo(img_float, CV_32F); // 테스트 데이터 float 형태여야 함
img_flatten = img_float.reshape(1, 1); // 1x20x20 -> 1x1x400
/* 예측 결과 확인 */
knn->findNearest(img_flatten, 3, res);
cout << cvRound(res.at<float>(0, 0)) << endl;
/* 초기화 */
img.setTo(0); // 행렬 0으로 초기화
imshow("img", img);
}
}
return 0;
}
Ptr <KNearest> train_knn() {
/* 데이터셋 */
Mat digits = imread("images/digits.png", IMREAD_GRAYSCALE);
if (digits.empty()) {
cerr << "Image load failed!" << endl;
return 0;
}
/* 훈련 데이터, 레이블 데이터 가공 */
Mat train_images, train_labels; // 훈련 데이터 행렬, 레이블 데이터 행렬
for (int j = 0; j < 50; j++) {
for (int i = 0; i < 100; i++) {
Mat roi, roi_float, roi_flatten;
roi = digits(Rect(i * 20, j * 20, 20, 20)); // ROI 20x20 pixel
roi.convertTo(roi_float, CV_32F); // 훈련 데이터 float 형태여야 함
roi_flatten = roi_float.reshape(1, 1); // 1x20x20 -> 1x1x400
train_images.push_back(roi_flatten); // train images 세로로 추가
train_labels.push_back(j / 5); // 0 ~ 4: 0, ..., 45 ~ 49: 9
}
}
/* 훈련 데이터, 레이블 데이터로 훈련 진행 */
Ptr<KNearest> knn = KNearest::create(); // kNearest 객체 생성하고 shared 포인터에 넣음
knn->train(train_images, ROW_SAMPLE, train_labels); // 훈련 진행
return knn;
}
void on_mouse(int event, int x, int y, int flags, void* userdata) {
Mat img = *(Mat*)userdata;
if (event == EVENT_LBUTTONDOWN) {
ptPrev = Point(x, y);
}
else if (event == EVENT_LBUTTONUP) {
ptPrev = Point(-1, -1);
}
else if (event == EVENT_MOUSEMOVE && (flags & EVENT_FLAG_LBUTTON)) {
line(img, ptPrev, Point(x, y), Scalar::all(255), 40, LINE_AA, 0);
ptPrev = Point(x, y);
imshow("img", img);
}
}
- 글씨 너무 작거나 크게 입력하거나 중앙이 아닌 곳에 입력하면 결과 잘못될 수 있음
머신러닝 & OpenCV #2 SVM, HOG (https://coollikethat.tistory.com/54) 로 이어집니다.
'Run > Computer Vision' 카테고리의 다른 글
| [Computer Vision] 딥러닝 & OpenCV (0) | 2023.10.11 |
|---|---|
| [Computer Vision] 머신러닝 & OpenCV #2 SVM, HOG (0) | 2023.10.11 |
| [Computer Vision] 영상 밝기와 명암비 조절 & 필터링 (0) | 2023.10.11 |
| [Computer Vision] OpenCV 주요 기능 (0) | 2023.10.11 |
| [Computer Vision] Mat 클래스 (0) | 2023.10.11 |