[Computer Vision] 딥러닝 & OpenCV
2023. 10. 11. 00:09ㆍRun/Computer Vision
1. 딥러닝
- 신경망(neural network): 사람의 뇌 신경 세포(neuron)에서 일어나는 반응을 모델링하여 만들어진 머신러닝 알고리즘
- = 인공신경망(artificial neural network)
- 딥러닝(deep learning): 신경망을 여러 계층으로 쌓아서 만든 머신러닝 알고리즘 중 하나
- = 심층 신경망(deep neural network)
- 보통 은닉층 2개 이상인 경우 딥러닝 알고리즘으로 간주

- 컴퓨터 비전 분야에서 딥러닝이 주목받고 있는 이유는 객체 인식, 분할 등 영역에서 기존 컴퓨터 비전 기반 기술보다 월등한 성능 보이기 때문
- 머신러닝: 특징(일반 pixel, HOG, ...)을 사람이 추출하여 입력으로 전달, 특징이 적합하지 않으면 좋은 성능 가지기 어려움
- 딥러닝: 특징 추출 및 학습을 모두 딥러닝이 알아서 수행, 대신 데이터는 훨씬 많이 필요


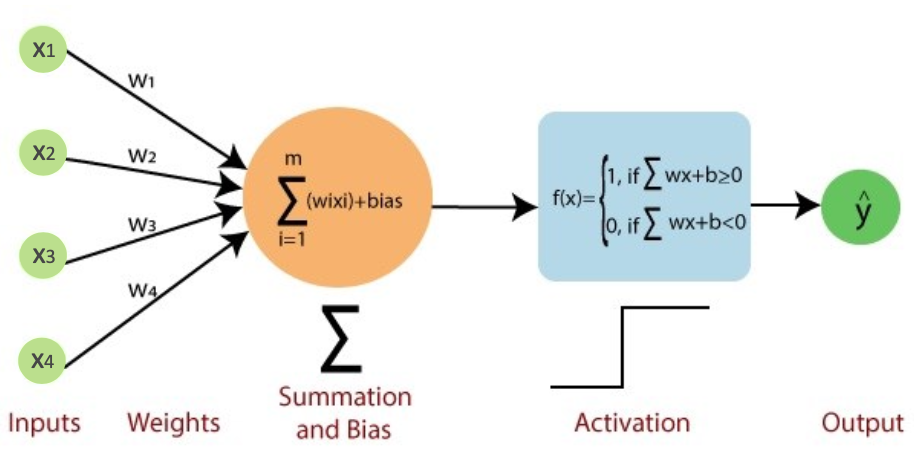
- 퍼셉트론(perceptron): 신경망의 가장 기초적인 형태 (1950년대 개발)
- 다수의 입력으로부터 가중합 계산하여 하나의 출력 만들어내는 구조
- 정점(node, vertex): 입력 노드 & 출력 노드
- 간선(edge): 가중치(weight)
- 편향(bias)
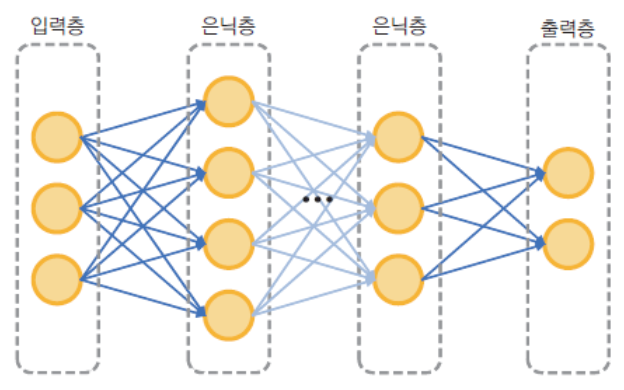
- 입력 노드, 출력 노드 개수 증가하고 여러 은닉층(hidden layer) 있는 형태로 좀 더 복잡한 문제 해결
- 신경망이 주어진 문제 제대로 해결하려면 신경망 구조가 적절해야 하고, 적절한 weight 부여되어야 함
- 적절한 weight, bias 찾기 위해 경사하강법(gradient descent), 오류 역전파(error backpropagation) 등 사용
- 학습 = 훈련 데이터셋 이용하여 적절한 weight, bias 찾는 과정
- 2000년대 초반까지 신경망 크게 발전 X (은닉층 많을수록 학습 시간 오래 걸리고 학습 제대로 되지 않음)
- 2000년대 후반부터 심층 신경망, 딥러닝 이름으로 크게 발전
- 1) 딥러닝 알고리즘 개선 → 은닉층 많아도 학습 제대로 이루어짐
- 2) 하드웨어(특히 GPU) 발전, GPU 이용한 학습 방법 → 훈련 시간 단축
- 3) 인터넷 발전에 따른 빅데이터(Pascal VOC, Coco, ImageNet, ...) 활용, 경쟁 및 공유 활발

- 다양한 딥러닝 구조 중 영상을 입력으로 사용하는 영상 인식, 객체 검출 등 분야에서는 CNN 구조가 널리 사용됨
- 보통 Convolution layer(합성곱 레이어. 2차원 영상에서 특징 추출) 여러 개, 맨 뒤에 FC layer(추출된 특징 분류)로 구성
- Convolution layer: 영상의 지역적인 특징 추출
- Pooling: 비선형 down sampling 수행하여 데이터 양 줄이고 일부 특징 강조 (max pooling, ...)
- FC layer: 앞서 추출된 특징 이용하여 출력값 결정
- Convolution 단계에서 사용하는 kernel 다양한 크기로 구성(1x1, 3x3, 5x5, ...), 레이어 사이 연결 방식도 다양
- 자연어 분야에서 사용하던 Transformer 구조(attention)를 컴퓨터비전 분야에 적용한 딥러닝 알고리즘이 우수한 성능 내고 있음
2. OpenCV DNN 모듈
- 이미 만들어진 네트워크에서 순방향 실행 (훈련 X 오로지 추론만)
- PyTorch, Tensorflow 등 다른 프레임워크에서 학습 진행하고, OpenCV DNN 모듈로 학습된 모델 불러와 추론
- OpenCV DNN 모듈은 C/C++ 기반이기 때문에 프로그램 이식성 높음
- OpenCV 3.3부터 기본 모듈에 포함
- 지원하는 딥러닝 프레임워크 (PyTorch는 ONNX 형식으로 변환 후 사용 가능)
- Caffe: https://caffe.berkeleyvision.org/
- Tensorflow: https://www.tensorflow.org/
- Torch: http://torch.ch/
- Darknet: https://pjreddie.com/darknet/
- DLDT: https://github.com/ni/dldt
- ONNX (공통 포맷): https://onnx.ai/
- 최근 새롭게 개발되고 있는 딥러닝 네트워크도 지속적으로 추가 지원
- 영상 인식: AlexNet, GoogLeNet, VGG, ResNet, SqueezeNet, DenseNet, ShuffleNet, MobileNet, Darknet, ...
- 객체 검출: VGG-SSD, MobileNet-SSD, Faster-RCNN, R-FCN, Mask-RCNN, EAST, YOLOv3, tiny YOLOv4, YOLOv4, ...
- OpenPose, Colorization, OpenFace, ...
- But, 대중적이지 않은 모델 업데이트 안하는 경우도 있음

- readNet(): 모델 읽어오는 함수
- model만으로는 모델 모양 정확히 알 수 없어 config를 넣기도 함

- cv::dnn::Net: 딥러닝 네트워크 표현
- dnn 모듈에 포함되어 있고 cv::dnn 네임스페이스 안에 정의되어 있음
- 다양한 레이어로 구성된 네트워크 구조 표현
- 네트워크에서 특정 입력에 대한 순방향 실행 지원 (훈련 지원 X)
- Net::empty(): 초기화 잘 되었는지 확인, true면 문제 있는 것
- Net::forward(): 네트워크 입력 설정
- Net::setInput(): 네트워크 순방향 실행
- Net::setPreferableBackend(): 선호하는 백엔드 지정 (ex. OpenCV)
- Net::setPreferableTarget(): 선호하는 타겟 디바이스 지정 (ex. CPU)


- Net 클래스 객체 직접 생성하지 않고 readNet() 사용하여 생성 (readNetFromXXX()도 사용 가능)
- 미리 학습된 딥러닝 모델, 네트워크 구성 파일 이용하여 생성
- model에 네트워크 훈련 가중치와 네트워크 구조 함께 저장되어 있으면 config 생략 가능 (ex. ONNX)
- model 또는 config 확장자 통해 framework 구분 가능한 경우 framework 생략 가능 (그냥 보통 생략)

- 네트워크에 Mat 타입 2차원 영상 그대로 입력하지 않고 blob 형식으로 변경해야 함
- Blob: 영상 등 데이터 포함할 수 있는 다차원 데이터 표현 방식, OpenCV에서는 Mat 타입 4차원 행렬
- N: 영상 개수 / C: 채널 개수 / H, W: 영상 세로, 가로 크기
- blobFromImage(): Mat 영상으로부터 blob 생성
- blobFromImages(): Batch(= 영상 여러 장) 변환하는 경우 사용
- blob 출력 포맷 = 딥러닝 모델 입력 포맷


- setInput(): Blob 객체 생성한 후 네트워크 입력으로 설정
- blobFromImage()와 마찬가지로 scalefactor, mean 인자 있음 (추가적으로 픽셀 값 조정 가능)
- mean은 채널별로 빼줄 수 있지만, scalefactor는 불가능함

- forward(): 네트워크 입력 설정한 후 네트워크 순방향으로 실행하여 결과 예측 (추론)
- Backend, Target 실행환경에 맞추어 설정
net = cv::dnn::readNet(modelFile, cfgFile);
// Case 1 (default) : 기본 OpenCV Backend & CPU 이용하여 추론
net.setPreferableBackend(cv::dnn::DNN_BACKEND_OPENCV);
net.setPreferableTarget(cv::dnn::DNN_TARGET_CPU);
// Case 2 : CUDA Backend & GPU 이용하여 추론
net.setPreferableBackend(cv::dnn::DNN_BACKEND_CUDA);
net.setPreferableTarget(cv::dnn::DNN_TARGET_CUDA);
// Case 3 : CUDA Backend & GPU(Float 16 연산) 이용하여 추론
net.setPreferableBackend(cv::dnn::DNN_BACKEND_)CUDA;
net.setPreferableTarget(cv::dnn::DNN_TARGET_CUDA_FP16);

3. MNIST 데이터셋 & Tensorflow 모델로 필기체 숫자 인식
- 각 숫자 영상 크기 28x28, 픽셀 값 0~1 실수 값, 그레이스케일
- Tensorflow로 학습한 네트워크 mnist_cnn.pb 불러와 사용 (학습 결과 & 네트워크 구성 정보 저장되어 있음)
#include <iostream>
#include "opencv2/opencv.hpp"
using namespace std;
using namespace cv;
using namespace cv::dnn;
Point ptPrev(-1, -1);
void on_mouse(int event, int x, int y, int flags, void* userdata);
int main() {
Net net = readNet("models/mnist_cnn.pb"); // 네트워크 생성
if (net.empty()) {
cerr << "Network load failed!" << endl;
return -1;
}
Mat img = Mat::zeros(400, 400, CV_8UC1);
imshow("img", img);
setMouseCallback("img", on_mouse, (void*)&img);
while (true) {
int c = waitKey(0);
// ESC 누르면 종료
if (c == 27) {
break;
}
// Space 누르면 글씨 인식, 결과 출력
else if (c == ' ') {
/* 추론 */
Mat inputBlob = blobFromImage(img, 1/255.f, Size(28, 28)); // blob 생성
net.setInput(inputBlob);
Mat prob = net.forward(); // 추론
/* 예측 결과 확인 */
double maxVal;
Point maxLoc;
minMaxLoc(prob, NULL, &maxVal, NULL, &maxLoc); // 가장 높은 값, 낮은 위치/값 구함 (내장함수)
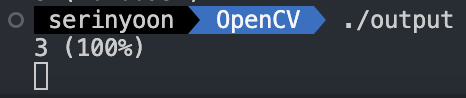
int digit = maxLoc.x;
cout << digit << " (" << maxVal * 100 << "%)" << endl;
/* 초기화 */
img.setTo(0); // 행렬 0으로 초기화
imshow("img", img);
}
}
return 0;
}
void on_mouse(int event, int x, int y, int flags, void* userdata) {
Mat img = *(Mat*)userdata;
if (event == EVENT_LBUTTONDOWN) {
ptPrev = Point(x, y);
}
else if (event == EVENT_LBUTTONUP) {
ptPrev = Point(-1, -1);
}
else if (event == EVENT_MOUSEMOVE && (flags & EVENT_FLAG_LBUTTON)) {
line(img, ptPrev, Point(x, y), Scalar::all(255), 40, LINE_AA, 0);
ptPrev = Point(x, y);
imshow("img", img);
}
}- 입력 그레이스케일 영상 img (0~255) → Blob (0~1, 1x1x28x28)
- 반환되는 행렬 prob: 10x1, CV_32FC1 (각 0~9에 해당할 확률)
- 인식 결과: 최댓값 위치 행 번호 / 해당 위치의 원소 값: 확률
- 머신러닝과 달리 인식 확률도 확인해볼 수 있음

'Run > Computer Vision' 카테고리의 다른 글
| [Computer Vision] 머신러닝 & OpenCV #2 SVM, HOG (0) | 2023.10.11 |
|---|---|
| [Computer Vision] 머신러닝 & OpenCV #1 머신러닝 개요, KNN (0) | 2023.10.11 |
| [Computer Vision] 영상 밝기와 명암비 조절 & 필터링 (0) | 2023.10.11 |
| [Computer Vision] OpenCV 주요 기능 (0) | 2023.10.11 |
| [Computer Vision] Mat 클래스 (0) | 2023.10.11 |