2023. 10. 17. 00:23ㆍRun/Machine Learning
Stanford University CS231n, Spring 2017
CS231n: Convolutional Neural Networks for Visual Recognition Spring 2017 http://cs231n.stanford.edu/
www.youtube.com
Activation Functions
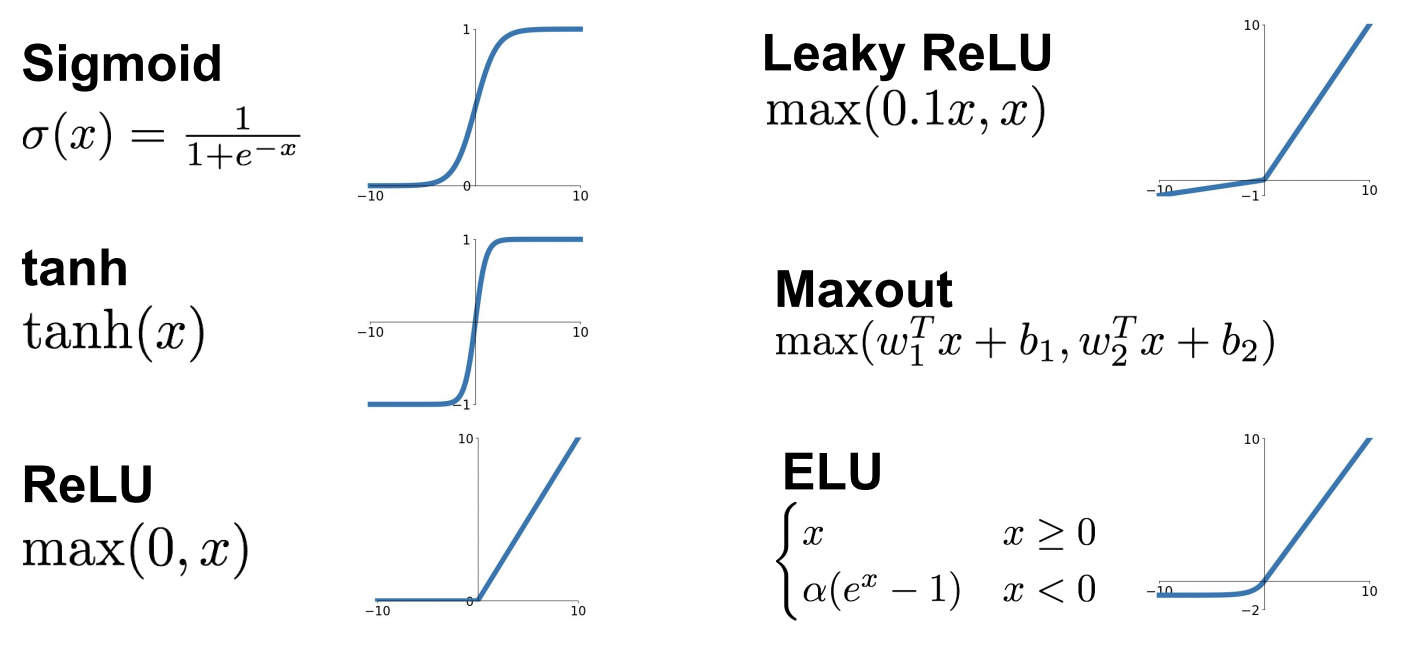
| Sigmoid | - 값을 입력받아 [0, 1] 사이 값 출력 - 입력값이 크면 출력값은 1에 가깝고, 작으면 0에 가까움 - 입력값이 크거나 작을 때 gradient가 0에 가까워져 back prop 시 0이 계속 전달됨 - 출력값이 zero-centered이 아님 (ex. 입력값이 항상 양수이면 gradient 부호가 계속 같으므로 같은 방향으로만 이동하게 됨) |
| tanh(x) | - 값을 입력받아 [-1, 1] 사이 값 출력 - zero-centered - 입력값이 크거나 작을 때 gradient가 0에 가까워져 back prop 시 0이 계속 전달됨 |
| ReLU | - 입력값이 음수면 0, 양수면 입력값 그대로 - 입력값이 양수일 때 saturation이 일어나지 않음 - AlexNet에서 처음 ReLU 사용 - not zero-centered - 입력값이 음수일 때 saturation (dead ReLU) - Dead ReLU에서 activate 발생하지 않고 update 되지 않음 |
일반적으로 ReLU가 가장 많이 쓰이고, Sigmoid는 가장 구식이고 LU 계열이 더 잘 동작함
Data Preprocessing

zero-centered: 모든 입력값이 양수면 weight update를 할 수 없는 문제 해결
normalized: 동일한 contribute를 위해 정규 분포로 normalize
Test 할 때에도 data preprocessing 해주어야 함
보통 zero-centered 까지만 하고, 다른 ML 문제와 달리 이미지에서는 normalization을 아주 잘 해줄 필요는 없음
Weight Initialization
Weight 초기값을 0으로 하면, 모든 뉴런이 같은 연산을 하고 output도 동일하고 gradient도 동일함
우리는 뉴런이 서로 다르게 동작하길 원하므로, weight를 랜덤하게 초기화하는 것이 좋음
Idea #1 Small random numbers
W = 0.01 * np.random.randn(D, H)Standard gaussian에서 sampling하고 크기를 줄이기 위해 scaling
작은 네트워크에서는 괜찮지만 깊은 네트워크에서는 좋지 않음

위 예시에서 tanh activation function을 사용하기 때문에 mean은 항상 0 근처이고
Standard deviation은 가파르게 줄어 0으로 수렴함
W 값이 아주 작기 때문에 W를 곱하면 곱할수록 output 값이 급격히 줄어드는 것임
Idea #2 Big random numbers
W = 1.0 * np.random.randn(D, H)반대로 weight를 큰 값으로 초기화하면 tanh 특성상 saturation 됨
이렇게 되면 값은 양극화되어 -1 또는 1이 되고, gradient는 0이 되어 weight update가 일어나지 않게 됨
따라서 너무 작지도, 너무 크지도 않은 적절한 값으로 초기화하는 것이 중요함
Idea #3 Xavier initialization
W = np.random.randn(fan_in, fan_out) / np.sqrt(fan_in)Standard gaussian으로 sampling 한 값을 input 개수로 scaling
Linear activation function을 사용한다는 가정 하에 잘 동작함 (ReLU 등 nonlinear 한 것에는 잘 동작하지 않음)
Idea #4 Dividing by 2
W = np.random.randn(fan_in, fan_out) / np.sqrt(fan_in / 2)ReLU는 output의 절반을 죽임
뉴런 중 절반이 죽는다는 것을 고려하여 2로 나눠주는 방식
Batch Normalization

Output activation을 강제로 unit gaussian (0~1) 으로 만드는 것
각 layer에서 나온 batch 단위 activation을 현재 batch에서 계산한 평균과 분산을 이용해 normalize하여 unit gaussian으로 만듦
Batch 간 분포 차이가 없도록 하여 학습이 잘 되도록 하기 위함
Weight를 잘 초기화하는 것 대신에 학습할 때마다 각 layer에 batch normalize하여 모든 layer가 unit gaussian이 되도록 할 수 있음
Learning Process
1. Data preprocessing
2. Architecture 고르기 (CNN, LSTM, ...)
3. Sanity check
네트워크 초기화한 후 forward pass 진행하여 loss 값을 계산함
초기 loss가 괜찮으면, regulization(1e3) 추가하여 loss 값 증가하는 것을 확인함
4. Train
데이터셋 일부만 학습시키고, regularization 하지 않고 loss 값 내려가는 것을 확인함
Epoch 마다 loss가 0으로 수렴해가는지 확인함
5. 적절한 Learning rate 찾기
전체 데이터셋에 regularization 하여 적절한 learning rate 찾음
Learning rate가 너무 작으면 gradient update가 충분히 일어나지 않아 loss 변화가 거의 없음
Learning rate가 너무 크면 loss 값이 NaN으로 나올 수 있음
'Run > Machine Learning' 카테고리의 다른 글
| [Machine Learning] CS231N #9 CNN Architectures (0) | 2023.10.26 |
|---|---|
| [Machine Learning] CS231N #7 Training Neural Networks 2 (0) | 2023.10.17 |
| [Machine Learning] CS231N #5 Convolutional Neural Networks (0) | 2023.10.16 |
| [Machine Learning] CS231N #4 Backpropagation and Neural Networks (0) | 2023.10.15 |
| [Machine Learning] CS231N #3 Loss Functions and Optimization (0) | 2023.10.14 |