2023. 10. 17. 16:52ㆍRun/Machine Learning
Stanford University CS231n, Spring 2017
CS231n: Convolutional Neural Networks for Visual Recognition Spring 2017 http://cs231n.stanford.edu/
www.youtube.com
여러 Optimization 방식들
SGD

SGD는 mini-batch에서의 loss를 계산하고 gradient의 반대 방향으로 이동하며 parameter vector를 update 하는 방식임
W1, W2 두 가중치가 있고 이를 최적화하고자 한다고 하자
Poor Conditioning
- W1는 수평축으로 weight가 변하고 W2는 수직축으로 weight가 변한다면 loss는 매우 느리게 변함
- Loss function은 아래로 움푹 파인 모양이어서, 수평축으로는 update가 느리고 수직축으로는 update가 빨라서 지그재그로 움직임

Local minima/Saddle point
- Local minma에 도달하면 SGD가 멈추고 더이상 update가 이루어지지 않음
- 데이터가 고차원일수록 더 잘 일어나고, saddle point 주변의 기울기가 매우 작아져 update도 매우 느려짐
Noise
- Mini-batch를 사용하면 gradient가 noisy 할 수 있음
- Loss function 공간을 비틀거리며 이동하면 minima까지 도달하는 데 오래 걸림
SGD + Momentum

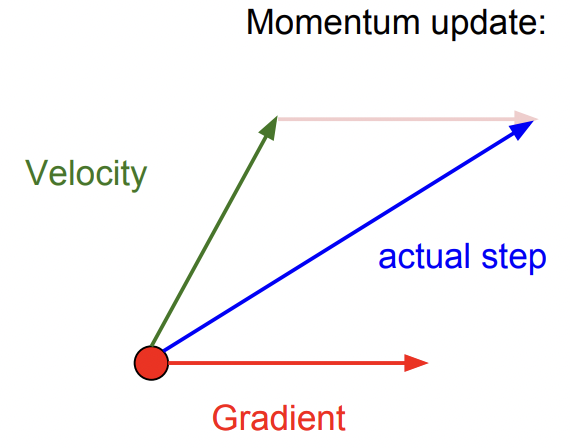
이런 SGD의 문제를 해결하기 위해 momentum term을 추가할 수 있음
SGD는 gradient 방향으로만 움직이고, SGD+Momentum은 gradient 방향과 velocity를 같이 고려하여 velocity vector 방향으로 나아감
Gradient가 0이어도 velocity를 가지고 있으므로 계속 내려갈 수 있음
Momentum이 지그재그로 움직이는 것을 상쇄하여, 수직축으로의 변동을 줄여줌
Velocity가 있으면 noise가 평균화됨
Nesterov Momentum
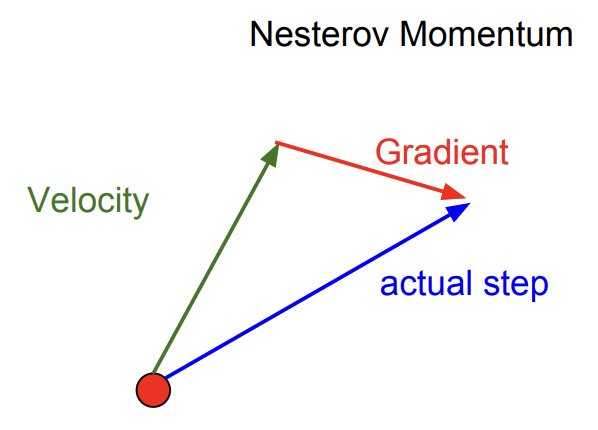
Momentum의 변형
빨간 점에서 시작해서 velocity 방향을 예측하여 그 지점에서의 gradient를 계산하고, 원점으로 돌아가 둘을 합침
Convex problem에서는 성능이 좋지만 neural network 같은 non-convex problem에서는 성능이 보장되지 않음
AdaGrad

grad_squared를 이용하는 방식 (gradient의 제곱값을 이용)
학습 중에 gradient의 제곱값을 grad_squared에 계속 더해나가 update step에서 나눠줌
그렇기 때문에 gradient 값이 작은 경우에는 속도가 잘 붙고, 값이 큰 경우에는 천천히 내려오게 됨
일반적으로 convex problem에서 더 성능이 좋고, non-convex problem에서는 saddle point에 걸릴 수 있음
RMSProp

AdaGrad의 변형
똑같이 grad_square를 이용하지만 학습하는 동안 값을 계속해서 축적시킴
Decay 값을 사용하므로 Momentum 방식과 비슷함
Adam
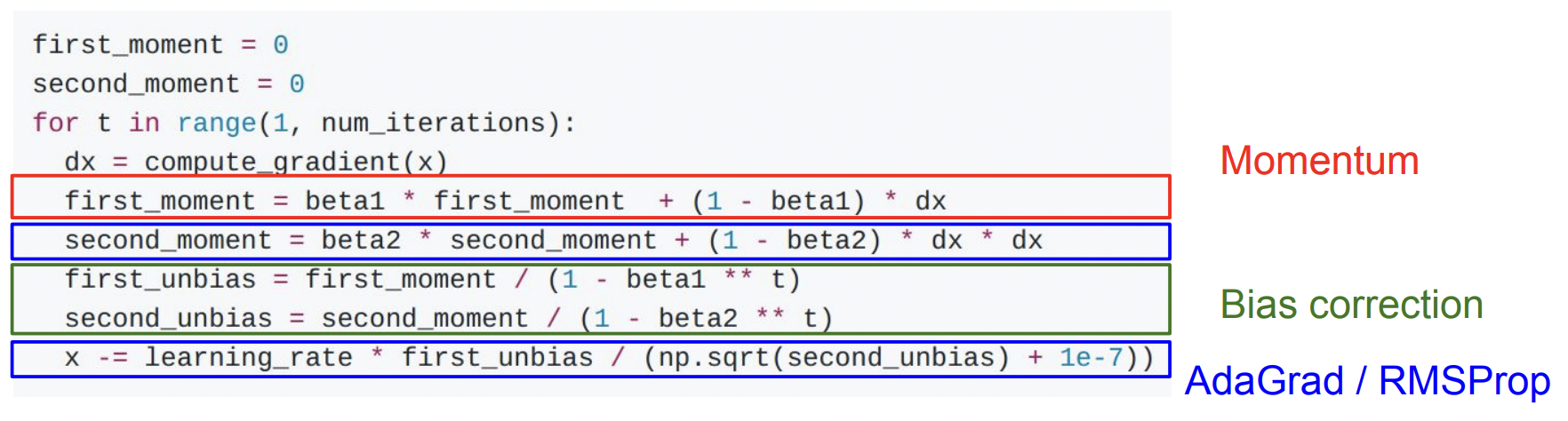
Momentum과 AdaGrad / RMSProp을 같이 사용하는 방법
초기 large step의 문제를 해결하기 위해 bias correction을 진행함
First-Order Optimization / Second-Order Optimization

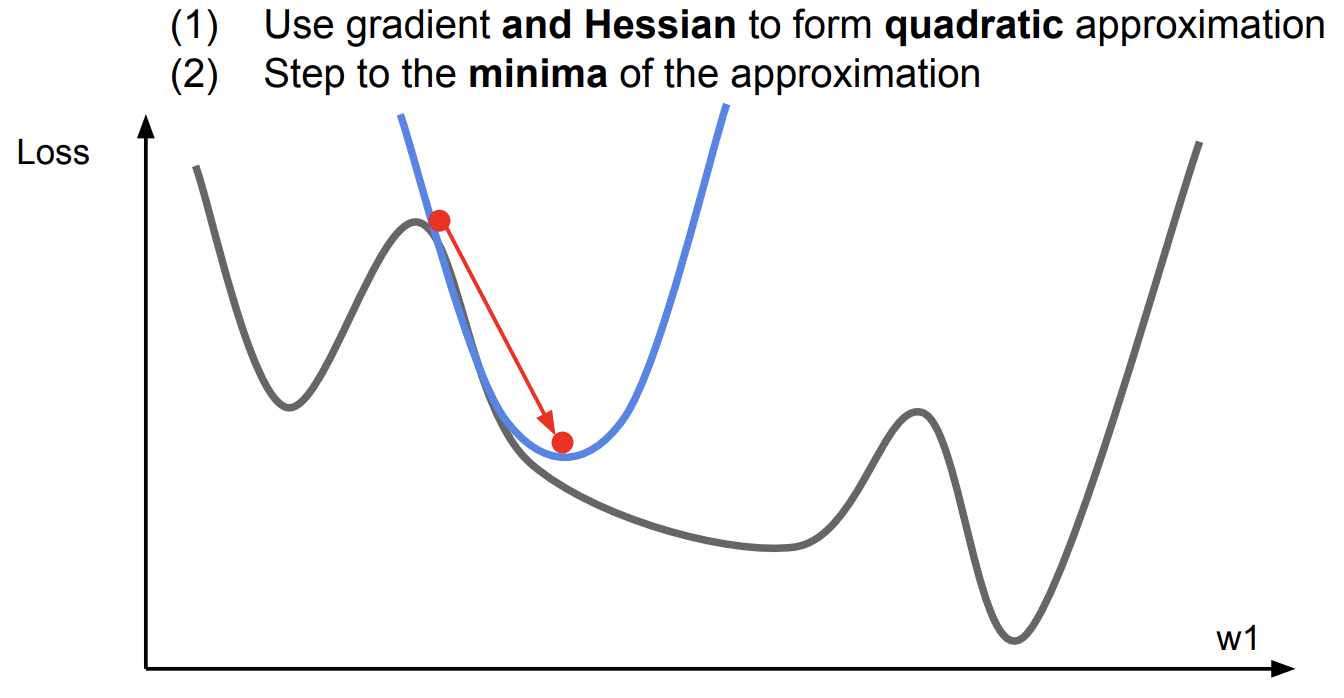
여태껏 도함수를 이용해 gradient 값을 구해 최적화를 해왔는데, 2차 함수를 통해 이동하는 방식도 있음
하지만 neural network은 고차원이라 연산량이 너무 많아 잘 사용하지 않음
Ensembles
여러 모델을 같이 사용하여 각 결과를 평균내는 방식
최종 성능에서 1~2% 정도의 성능을 끌어올릴 때 많이 사용함
여러 Reularization 방식들
Dropout Regularization
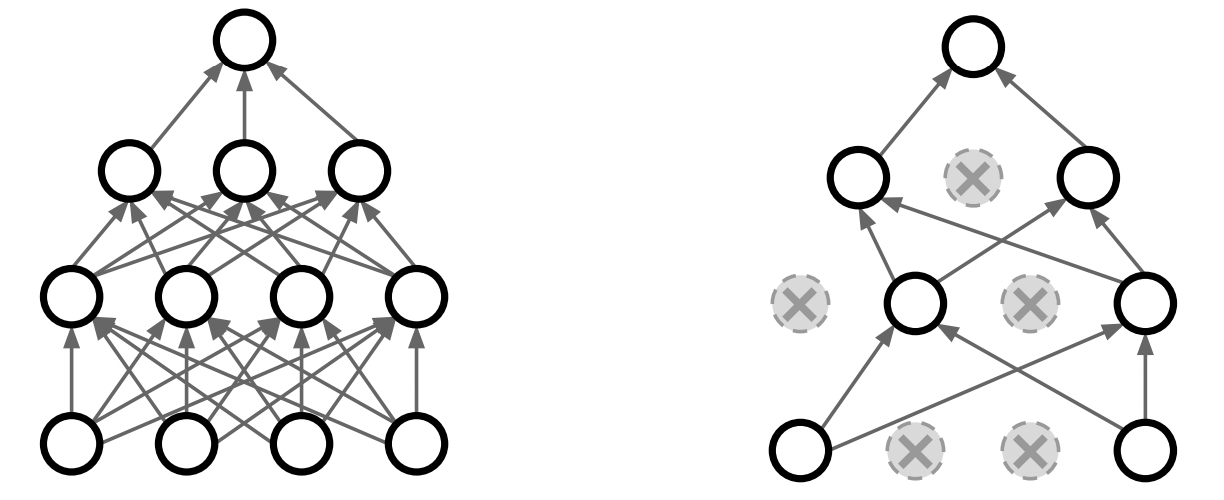
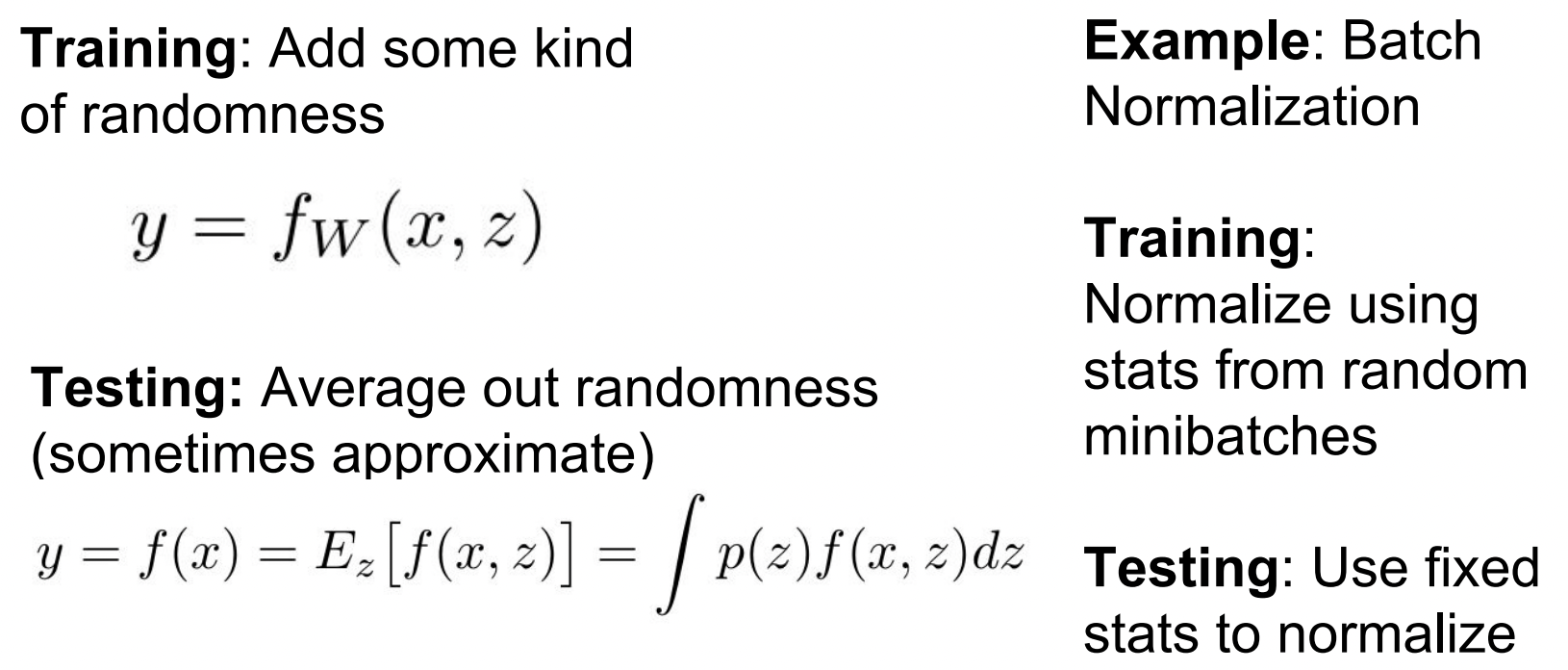
앞서 다룬 L1, L2 regularization은 neural network에서 많이 사용되지 않음
가장 효과적인 방식은 dropout regularization임
임의로 layer에 dropout을 넣어주는데, 이를 통해 노드들을 랜덤하게 버리게 됨 (노드의 activation 값을 0으로 만듦)
대부분 FC layer에서 적용하지만, CNN layer에서도 가끔식 적용함
각 노드를 이미지의 특정 부분을 담당하는 전문가라고 할 때,
dropout을 사용하면 전문가의 능력을 저하시키는 것이 아니라, 랜덤으로 전문가의 수를 줄여 overfitting을 막는 것임
Test에서 randomness는 좋지 않으므로, randomness를 average out하여 일반화시킴
Data Augmentation

이미지를 transform 하여 변형된 이미지로 학습을 시키는 방식
변형 방식으로는 horizontal flips, random crops/scales, color jitter, translation, rotation, stretching 등이 가능함
대표적인 regularization 방식은 dropout, batch normalization, data augmentation 임
Train과 test error 간의 차이를 줄이기 위해 이러한 regularization 방식을 사용함
Transfer Learning
데이터가 충분하지 않아서 overfitting이 발생할 수 있음
이를 막기 위해 regularization을 하는 것이고, 아니면 transfer learning을 해줄 수도 있음
데이터가 많이 없어도 overfitting을 방지하는 방법임
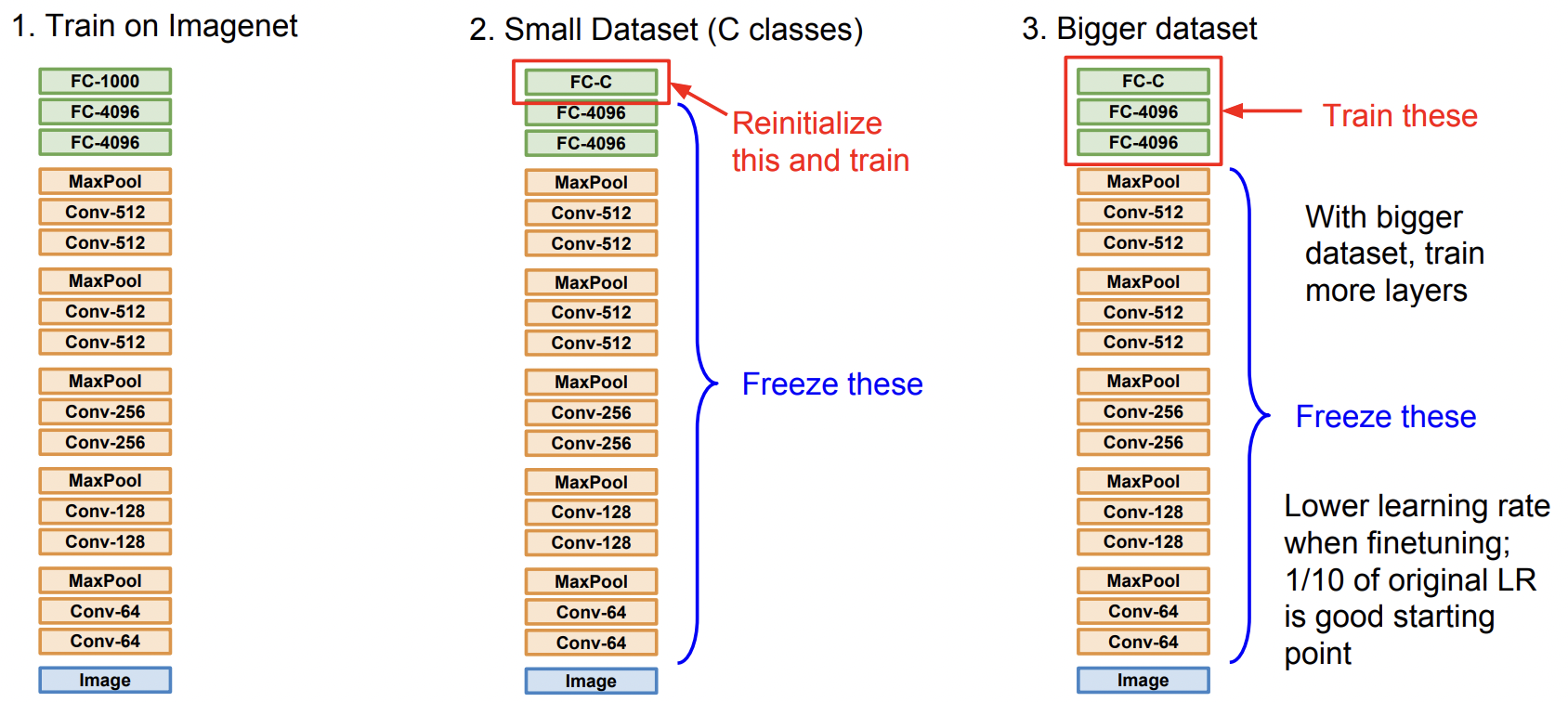
먼저 큰 데이터셋(ex. ImageNet)으로 학습을 시키고, 학습시킨 모델을 다시 현재의 작은 데이터셋에 사용함
마지막 FC layer에서 필요에 맞게 output dimension을 바꿔줌

요즘은 이처럼 pre-trained된 모델을 사용하여, 필요에 맞게 fine-tuning 하는 방법을 사용함
(ex. Fine-tuned Pre-trained VGG-16)
'Run > Machine Learning' 카테고리의 다른 글
| [Machine Learning] CS231N #10 Recurrent Neural Networks (2) | 2023.10.26 |
|---|---|
| [Machine Learning] CS231N #9 CNN Architectures (0) | 2023.10.26 |
| [Machine Learning] CS231N #6 Training Neural Networks 1 (0) | 2023.10.17 |
| [Machine Learning] CS231N #5 Convolutional Neural Networks (0) | 2023.10.16 |
| [Machine Learning] CS231N #4 Backpropagation and Neural Networks (0) | 2023.10.15 |