2023. 10. 26. 15:29ㆍRun/Machine Learning
Stanford University CS231n, Spring 2017
CS231n: Convolutional Neural Networks for Visual Recognition Spring 2017 http://cs231n.stanford.edu/
www.youtube.com
(Vanilla) Neural Network & RNN
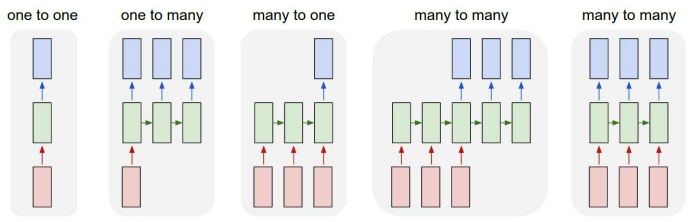
One-to-One: vanilla neural network
네트워크는 이미지 또는 벡터를 입력받고, 입력 하나가 hidden layer를 거쳐 하나의 출력을 내보냄
하지만 머신러닝 관점에서 모델이 다양한 입력을 처리할 수 있도록 유연해질 필요가 있음 → RNN
One-to-Many: 단일 입력 & 가변 출력 (ex. Image Captioning: Image → Sequence of words)
Many-to-One: 가변 입력 & 단일 출력 (ex. Sentiment Classification: Sequence of words → Sentiment)
Many-to-Many: 가변 입력 & 가변 출력 (ex. Machine Translation: Sequence of words → Sequence of words)
Sequential Processing of Non-Sequence Data
RNN은 가변 입력, 가변 출력 뿐 아니라 고정된 크기의 입력, 출력에 대해서도 유용함
ex. MNIST: feed forward pass 한 번만 하는 게 아니라 이미지의 여러 부분을 조금씩 살펴보고 최종적으로 판단하기
RNN

일반적으로 RNN은 작은 Recurrent Core Cell을 가짐
Input x가 RNN으로 들어가고, RNN는 내부에 hidden state를 가지고 있음
Hidden state는 RNN이 새로운 input을 불러들일 때마다 update 됨
Hidden state는 모델에 feedback 되고, 이후에 다시 새로운 input x가 들어옴
1. RNN이 입력을 받음
2. Hidden state를 update 함
3. 출력값을 내보냄

RNN blcok은 함수 f를 통해 재귀적인 관계를 연산할 수 있도록 설계됨
h_t-1: 이전 상태의 hidden state
x_t: 현재 상태의 input
h_t: 다음 상태의 hidden state (updated hidden state)
RNN에서 출력값 y를 가지려면, h_t를 입력으로 하는 FC-layer을 추가해야 함
FC-layer는 매번 update 되는 hidden state(h_t)를 기반으로 출력값을 결정
함수 f와 파라미터 W는 매번 동일함
(Vanilla) RNN
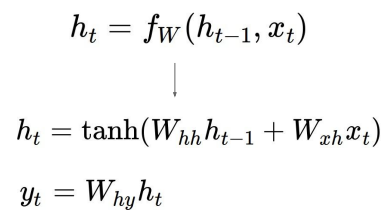
Weight matrix W_xh와 입력 x_t의 곱
W_hh는 이전 hidden state(h_t-1)와 곱해짐
시스템에 non-linearity를 구현하기 위해 tanh 적용 → 왜 굳이 tanh인가?
RNN: Computational Graph
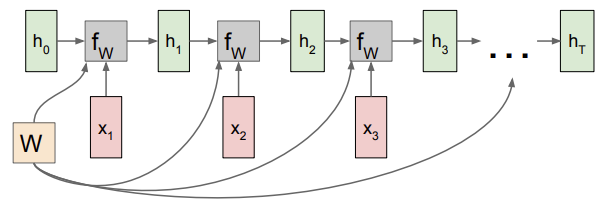
첫 step에는 initial hidden state인 h_0 (대부분 0으로 초기화), 입력 x_1가 있음
h_0와 x_1이 함수 f_w의 input으로 들어감, 출력은 h_1, x)2와 함께 다음 input으로 들어감, ...
매번 동일한 가중치 행렬 W가 사용됨
Backward pass 시 dLoss/dW를 계산하려면 행렬 W의 gradient를 전부 더해줘야 함
RNN의 backprop을 위한 행렬 W의 gradient를 구하려면, 각 스텝에서의 W에 대한 gradient를 전부 계산한 뒤 모두 더함
RNN: Computational Graph: Many to Many
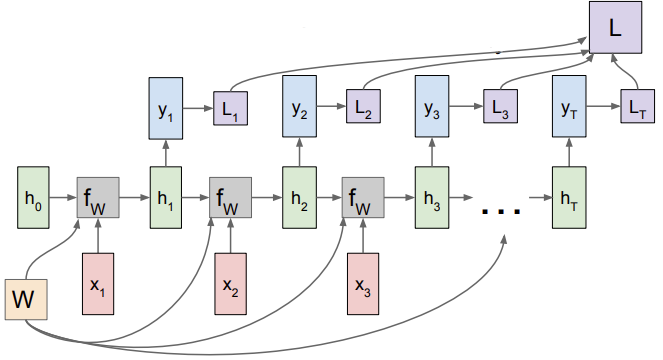
출력값 h_t가 다시 입력으로 들어가 y_t 만들어 냄
각 sequence마다 ground truth label이 있다면 각 스텝마다 개별적으로 y_t에 대한 loss 계산할 수 있음 (ex. softmax loss)
RNN의 최종 loss는 각 개별 loss들의 합
Backprop을 생각해보면, 모델을 학습시키려면 dLoss/dW를 구해야 함 → loss flowing은 각 스텝마다 이루어짐
RNN: Computational Graph: Many to One
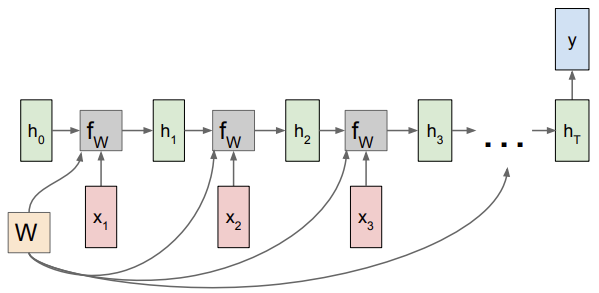
최종 hidden state에서만 결과값이 나옴
RNN: Computational Graph: One to Many
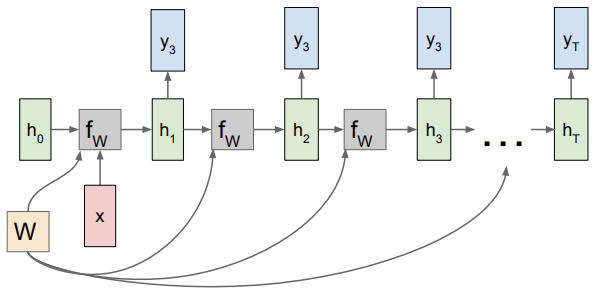
대게 고정 입력은 모델의 initial hidden state를 초기화시키는 용도로 사용됨
모든 스텝에서 출력값 가짐
RNN: Computational Graph: Many to One + One to Many
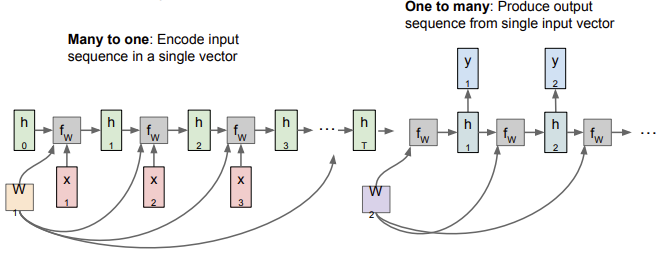
Encoder (Many-to-One): 가변 입력을 받음 (ex. english sentence) → final hidden state 통해 하나의 벡터로 요약
Decoder (One-to-Many): 단일 입력을 받음 (하나의 벡터) → 가변 출력 내뱉음 (ex. 다른 언어로 번역된 sentence)
가변 출력은 매 스텝 적절한 단어를 내뱉음
Output sentence의 각 loss를 합해 backprop 진행
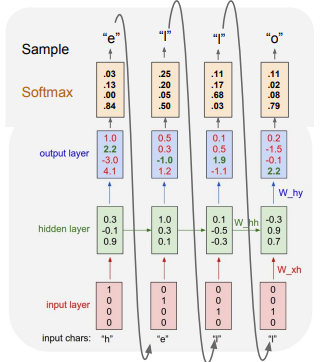
RNN은 Language modeling에서 자주 사용
Language modeling 문제에서 하고싶은 것은 어떻게 자연어를 만들어낼지
위 예제에서 네트워크는 문자열 sequence를 읽어들이고, 현재 문맥에서 다음 문자를 예측해야 함 (hell → hello)
Training time에서 training sequence(hello)의 각 단어들을 입력으로 넣어주어야 함
'h', 'e', 'l', 'o' 4종류이므로 h는 [1, 0, 0, 0] e는 [0, 1, 0, 0] l은 [0, 0, 1, 0], o는 [0, 0, 0, 1] 벡터로 표현 가능
우선 첫 스텝에서 입력 문자 'h'가 들어오고, y_t 출력함 (y_t: 'h' 다음에 어떤 문자가 나올지 예측한 값)
다음 스텝에서 입력 문자 'e'가 들어오고, ... 반복
결국 모델은 이전 문장의 문맥을 참고해서 다음 문자가 무엇일지를 학습해야 함
학습한 후에는 모델로부터 sampling (모델이 봤을 법한 문장을 모델 스스로 생성해내는 것)
매 스텝마다 출력값 존재, 이 출력값들의 loss를 계산해 final loss 구함 = backpropagation through time
Backpropagation through time
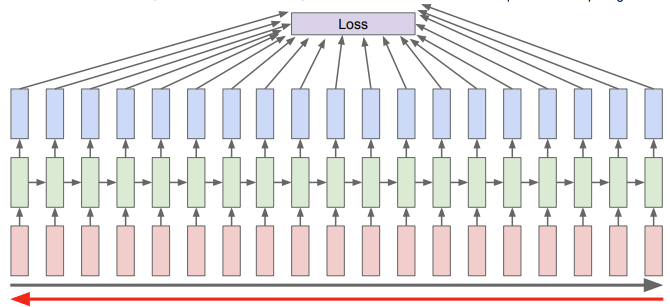
Forward pass의 경우 전체 sequence가 끝날 때까지 출력값이 생성됨
Backward pass의 경우 전체 sequence를 가지고 loss 계산해야 함
Sequence가 아주 긴 경우에 문제가 됨 (매우 느림) → Truncated Backpropagation through time 사용
Truncated Backpropagation through time
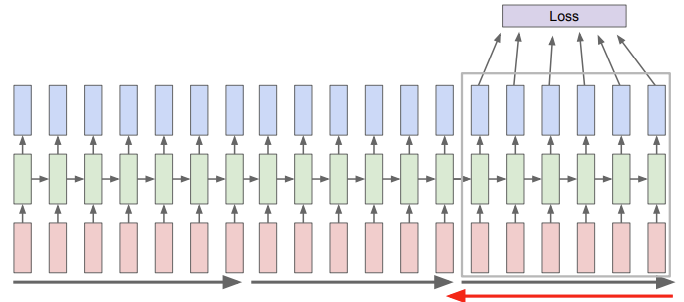
Train time에 한 스텝을 일정 단위로 자름 (ex. 100)
100 스텝만 forward pass 진행하고, 이 subsequence의 loss 계산하고 gradient step 진행
과정 반복, 이전 batch에서 계산한 hidden states는 계속 유지, 다음 batch의 forward pass 진행할 때 이전 hidden state 사용
Gradient step은 현재 batch에서만 진행
Image Captioning

Input: Image / Output: Caption (가변 출력)
입력 이미지를 받기 위해 CNN 사용, 이미지 정보가 들어있는 vector 출력
Vector는 RNN의 초기 step의 입력으로 들어감

모델을 학습시킨 후 test time에는 우선 입력 이미지를 받아 CNN의 입력으로 넣음
이때 softmax scores를 사용하지 않고, 직전의 4096-dim vector(FC-4096)를 사용
이 vector를 이용해 전체 이미지 정보를 요약하는 데 사용
모델이 직접 데이터 생성해내려면 초기 값을 넣어줘야 함
이전까지의 모델에서는 RNN이 2개의 가중치 행렬을 입력으로 받음 (현재 스텝의 W, 이전 스텝의 hidden state)
여기에 이제 추가로 이미지 정보를 입력해줘야 함 → 가장 쉬운 방법: 3번째 가중치 행렬 Wih 추가하기
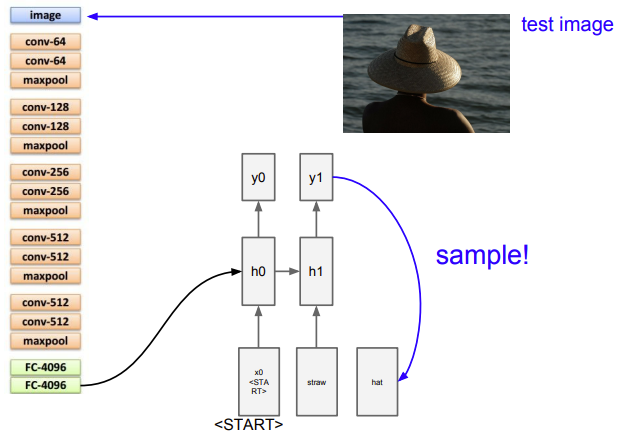

Image Captioning에 쓰이는 가장 큰 dataset: Microsoft COCO
RNN에서 좀 더 발전된 모델 = Attention
'Run > Machine Learning' 카테고리의 다른 글
| [Machine Learning] CS231N #12 Visualizing and Understanding (1) | 2023.11.12 |
|---|---|
| [Machine Learning] CS231N #11 Detection and Segmentation (1) | 2023.10.30 |
| [Machine Learning] CS231N #9 CNN Architectures (0) | 2023.10.26 |
| [Machine Learning] CS231N #7 Training Neural Networks 2 (0) | 2023.10.17 |
| [Machine Learning] CS231N #6 Training Neural Networks 1 (0) | 2023.10.17 |