2023. 11. 12. 15:01ㆍRun/Machine Learning
Stanford University CS231n, Spring 2017
CS231n: Convolutional Neural Networks for Visual Recognition Spring 2017 http://cs231n.stanford.edu/
www.youtube.com
이번 강의에서는 CNN layer의 데이터를 시각화하는 방법을 다룸

CNN의 첫 번째 layer를 시각화해보자
학습된 Weight를 시각화해보면 필터가 무엇을 인식하고자 하는지 대략 보임
필터의 layer는 점점 더 곱해지고, 나중에는 직관적으로는 이해할 수 없는 필터가 됨

네트워크의 마지막에서 FC layer을 통해 데이터를 4096차원으로 flatten 하고,
그렇게 생성된 feature vector는 nearest neighbor로 시각화됨
Feature vector을 nearest neighbor로 돌리면, 위와 같이 비슷한 이미지끼리 카테고리화됨
이 4096차원 feature vector를 2차원으로 축소시켜 시각화해보자

t-SNE와 PCA로 2차원 군집화를 할 수 있음 (예전에 해커톤 때 사용했던 기억이 난다)
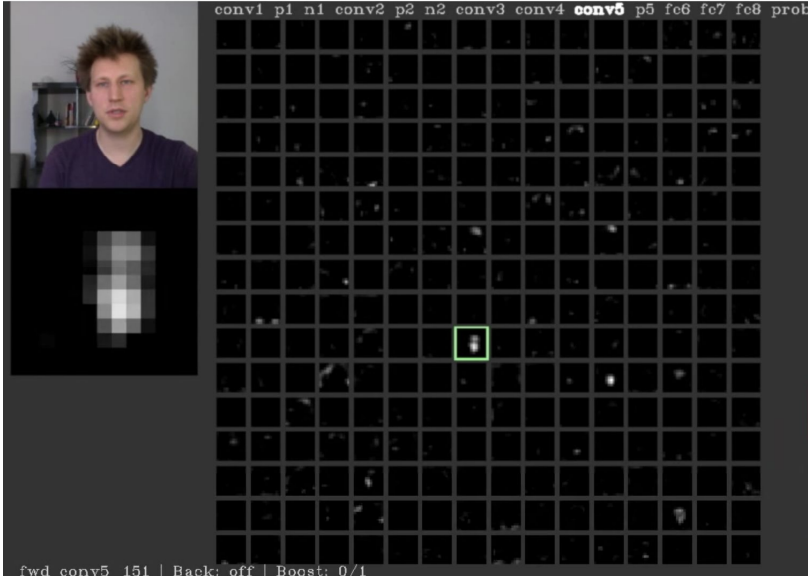
Feature map을 시각화하면 이런 식임
이미지 내에서 사람의 얼굴이 있는 부분만 활성화 되어있는 layer가 있음을 확인할 수 있음

Maximally Activating Patches는 이미지의 어느 부분이 카테고리를 결정짓는 근거가 되는지에 대한 것임
핵심 아이디어는 이미지에서 특정 patch를 뽑아 가린 후에 네트워크의 예측의 확률값을 계산하고,
이를 sliding window 방식으로 진행한 다음, 확률이 현저히 줄어드는 부분을 확인하는 것임

Occlusion Experiments는 이미지의 일부를 가린 후 카테고리 예측을 잘 하는지 확인하는 것임
이를 통해 이미지 내에서 어느 부분이 중요한지 알 수 있음


Saliency Maps도 비슷함
이미지를 Saliency Map으로 표현하면 객체의 형상을 볼 수 있음

Gradient Ascent는 Gradient Descent의 반대 개념이라고 생각하면 됨
Gradeint Ascent는 이미 학습이 된 네트워크의 weight를 고정시켜두고,
score가 최대가 되는 방향으로 빈 이미지를 넣어 synthetic 이미지를 만들어내는 것임
이때 overfitting을 방지하기 위해 regurlarization function을 추가함
즉, synthetic 이미지를 좀 더 자연스럽게 만들도록 해줌


먼저 이미지의 픽셀 값을 0으로 초기화함
Forward pass를 통해 생성된 weight를 고정시키고, 네트워크에 집어넣어 score을 계산함
이미지 픽셀의 뉴런 값의 gradient를 backprop으로 구하고, 픽셀 단위로 update함
이를 통해 최대 score을 가진 이미지를 만들어낼 수 있음 (색상은 무시!)


구글에서 나온 DeepDream


Feature map들로 이미지의 특징들을 통해 이미지를 재구성함
이전까지는 원본 이미지에서 feature을 뽑아내는 것에 중점을 두었는데,
이거는 feature에서 이미지를 다시 생성해보는 것임 (Inversion)
핵심은 새로 생성된 feature map의 vector과 원본 이미지의 feature vector 간의 distance를 최소화하는 것
Layer가 깊어질수록 픽셀, 색상, 텍스쳐와 같은 정확히 따라가기 어려운 낮은 수준의 정보는 버리고
전체적인 구조와 같은 좀 더 의미있는 정보들을 남기는 것임


Texture synthesis는 input으로 texture patch를 받으면 동일한 texture을 더 크게 만드는 것이 목표
단순한 texture에 대해서는 nearest neighbor만으로도 충분한데, 복잡한 texture에 대해서는 별로임
이에 neural network를 사용한 neural texture synthesis 방식이 고안됨


Input image를 neural network에 넣고 특정 layer에서 feature map을 가져와 gram matrix를 생성함
Gram matrix는 서로 다른 공간에 있는 채널들을 가지고 외적을 계산해 만든 matrix임
이는 feature vector간 다양한 상관 관계를 한 번에 나타날 수 있도록 만들어짐
Input image를 넣고 pre-trained된 네트워크에서 gram matrix를 생성함
랜덤 노이즈로 초기화된 image를 네트워크에 통과시켜 gram matrix를 생성함
두 gram matrix를 비교하여 L2 distance가 최소가 되도록 loss를 계산함
Back propapagation을 통해 이미지 픽셀의 gradient를 계산함
Gradient ascent을 통해 이미지 픽셀 값을 update 함
이 과정을 반복하여 input image와 유사한 이미지가 만들어지도록 함
얕은 layer에서 생성한 gram matrix를 가지고 이미지를 생성한 경우에는 공간적 구조를 잘 살리지 못함
깊은 layer에서 생성한 gram matrix를 사용해야 texture synthesis에 잘 활용할 수 있음

Neural texture synthesis를 artwork에 적용하여, Neural style transfer가 나오게 됨
Gram matrix를 재구성하는 것과, feature을 재구성하는 것을 합하여 만들어진 결과가 neural style transfer임
Input은 두 개가 있는데,
Content image는 최종 이미지가 어떻게 생겼으면 좋겠는지 알려주는 이미지이고
Style image는 최종 이미지의 texture가 어떻게 생겼으면 좋겠는지 알려주는 이미지임
최종 이미지는 content image의 feature reconstruction loss를 최소화하고,
style image의 gram matrix reconstruction loss도 최소화하도록 만들어진 이미지임

수많은 forward, backward 과정을 거쳐야 하기 때문에 느리다는 단점이 있음
이에 합성하고자 하는 이미지의 최적화를 전부 수행하지 않고, content image만을 input으로 받아 단일 네트워크를 학습시킬 수 있음
학습 시에는 content loss와 style loss를 동시에 학습시키고 네트워크 가중치를 update 함
학습은 오래 걸리지만 학습이 한 번 끝나면 이미지를 네트워크에 통과시키기만 하면 결과를 바로 볼 수 있음
'Run > Machine Learning' 카테고리의 다른 글
| [Machine Learning] AE, VAE, GAN (1) | 2023.11.22 |
|---|---|
| [Machine Learning] CS231N #11 Detection and Segmentation (1) | 2023.10.30 |
| [Machine Learning] CS231N #10 Recurrent Neural Networks (2) | 2023.10.26 |
| [Machine Learning] CS231N #9 CNN Architectures (0) | 2023.10.26 |
| [Machine Learning] CS231N #7 Training Neural Networks 2 (0) | 2023.10.17 |