2023. 11. 22. 17:07ㆍRun/Machine Learning
참고자료를 기반으로 정리한 글입니다.
AE, VAE, GAN) https://velog.io/@idj7183/AE-VAE
GAN) https://blog.naver.com/euleekwon/221557899873
AutoEncoder
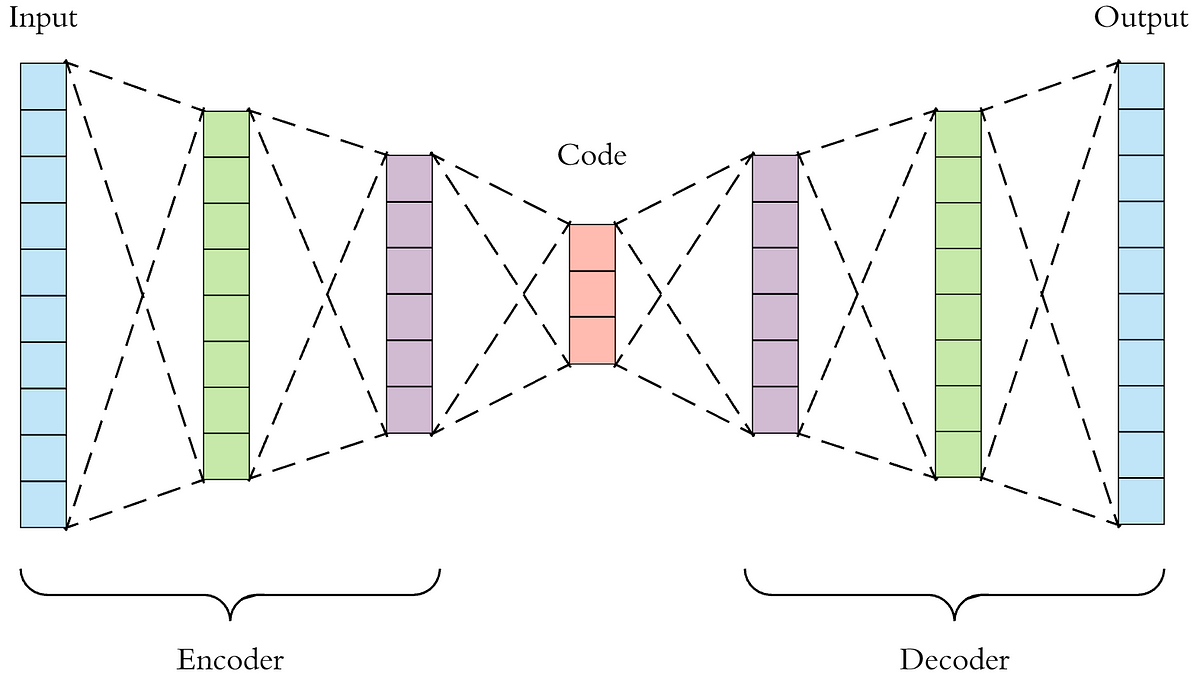
입력과 출력이 같은 구조로써, 중간에 bottleneck hidden layer을 활용하여 encode, decode를 수행함
높은 차원을 낮은 차원으로 변경하는 과정에서 원본 데이터 중 의미 있는 속성들을 추출하는 dimensionality reduction을 수행함
고차원 데이터를 에러 없이 잘 표현하는 subspace를 manifold라고 하는데, AE는 manifold learning을 통해 학습이 진행됨
Manifold learning의 목적은 차원을 잘 축소하여 데이터의 특징을 잘 추출하는 것임
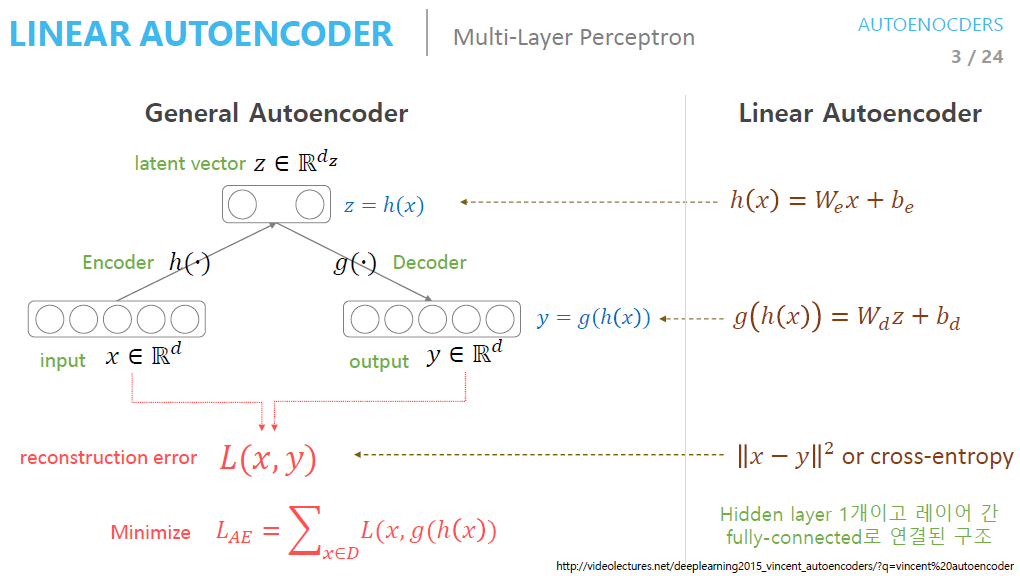
Input data를 encoder network에 통과시켜 latent vector $z$을 얻음
Latent variable은 latent vector들을 모아 놓은 hidden layer임 (= Bottleneck layer = Feature = Hidden representation)
Latent vector $z$를 decoder network에 통과시켜 input data와 같은 크기의 output을 생성함
Loss는 input data $x$와 decoder를 통과한 $y$의 차이값임
Variational AutoEncoder (VAE)
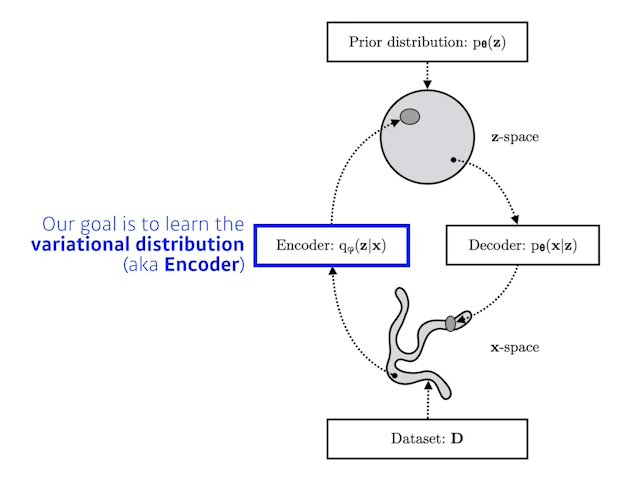
AutoEncoder는 이미지를 latent space, 즉 연속적인 실수 공간으로 mapping 하는 것임. 하지만 이미지는 연속적이지 않음
만약 latent space 중 mapping이 되어 있지 않은 빈 공간이 decoder의 입력으로 들어가게 되면 이미지의 품질이 매우 낮음
이에 Variational AutoEncoder가 탄생함
VAE는 AutoEncoder의 개념을 활용한 generative model로, expicit density이긴 하나 approximate density model임
Input data에 대한 model을 구할 수는 없지만, input data model에 근사하는 model을 형성함
AE는 latent variable에 값을 저장하지만, VAE는 latent variable에 확률 분포를 저장하므로 평균과 분산 파라미터를 생성함
또한 AE는 manifold learning이지만 VAE는 generative model이라는 점에서 다름
AE의 목적은 input $x$에 대해 자신을 언제든 reconstruct 할 수 있는 $z$를 만드는 것임
즉, encoder을 학습시켜 latent vector $z$을 만드는 것이 목표이며, 학습을 위해 decoder을 뒤에 붙인 것임
VAE의 목적은 input $x$가 만들어지는 확률 분포를 찾고, 다른 data에 대해 이 확률 분포를 활용하는 것임
즉, decoder을 학습시키고 latent vector $z$를 통과시켜 output을 얻는 것이 목표이며, 학습을 위해 encoder을 앞에 붙인 것임
Generative Adversarial Network
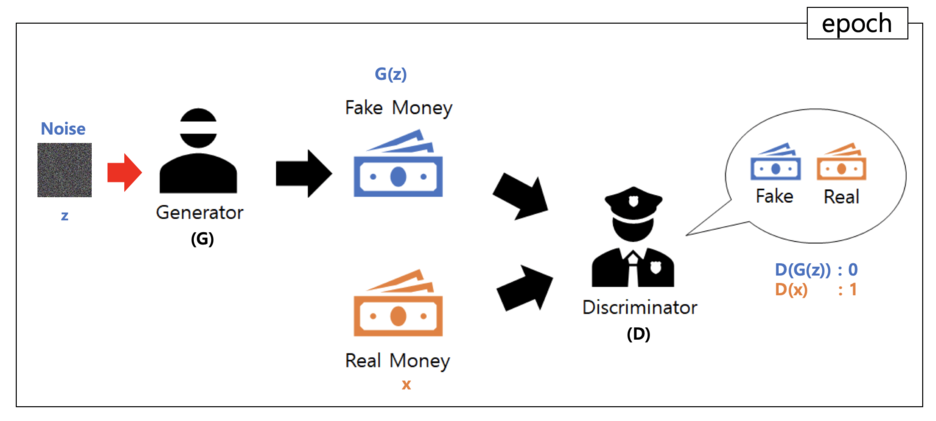
쉽게 설명하자면, 위조 지폐범이 위조 지폐를 만들면 경찰이 해당 지폐가 진짜인지 아닌지 구별하게 되고,
이를 반복하다 보면 위조 지폐범이 점차 더욱 진짜 같은 위조 지폐를 만든다는 것
- 0과 1이 랜덤하게 뿌려진 noise $z$를 생성함
- 해당 noise를 가지고 위조 지폐범 $G$이 위조 지폐 $G(z)$를 만듦
- 경찰 $D$가 위조 지폐 $G(z)$와 진짜 지폐 $x$를 구분하려고 함
만약 위조 지폐로 구분되면 0을 출력하고, 진짜 지폐로 구분되면 1을 출력함
이에 따라, $D(G(z))$는 0, $D(x)$는 1을 출력하게 됨
이 과정이 1 epoch이고, epoch을 반복하다가 엄청 완벽한 위조 지폐가 탄생하면
경찰은 더이상 지폐를 구분하지 못하기 때문에 확률이 50%가 되고 학습이 종료됨
❓ 확률 분포
확률 분포는 generator가 들어가는 모든 모델에서 다루는 개념임
| $X$ | 1 | 2 | 3 | 4 | 5 | 6 |
| $P(X)$ | 1/6 | 1/6 | 1/6 | 0/6 | 0/6 | 3/6 |
주사위를 여섯 번 던졌을 때 위와 같은 결과가 나왔다고 하자
이를 확률 분포 그래프로 표현하면, 아래와 같음
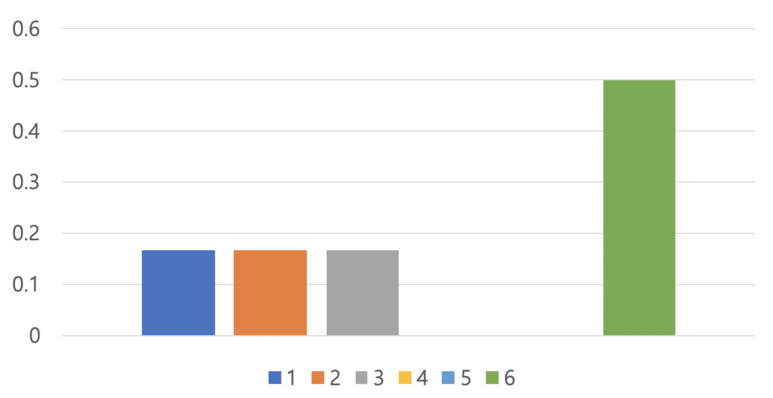
위 예시는 주사위를 다루고 있으므로 6개 뿐이지만, $X$가 이미지 데이터 한 장 한 장을 표현한다고 생각해보면
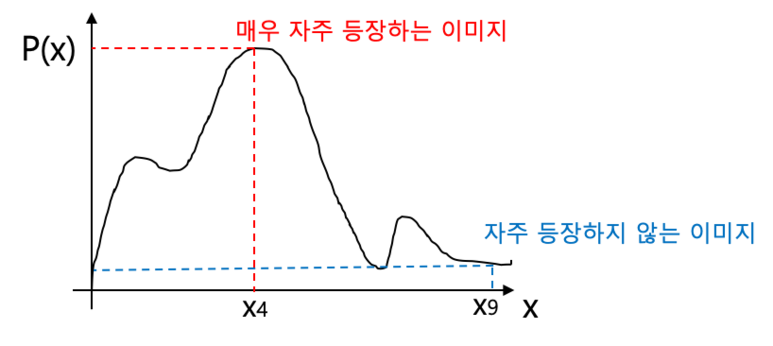
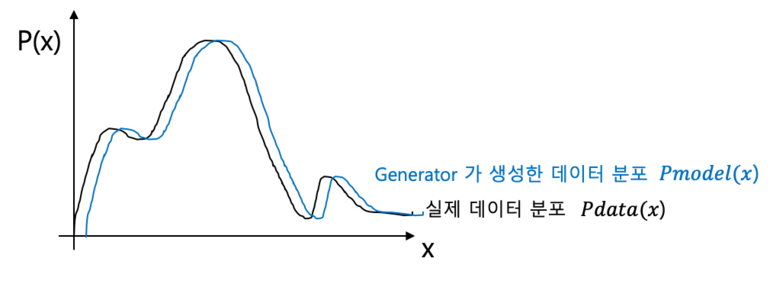
이러한 그래프가 나올 것이고, generator는 실제 데이터 분포가 나타내는 확률 분포 그래프와 유사한 모델을 제작하고자 하는 것임
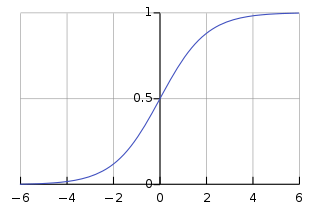
GAN에서는 discriminator 모델이 진짜 이미지와 가짜 이미지를 구분하도록 학습시킴
0과 1로 값을 구분할 때는 sigmoid 함수를 사용해 0.5를 기준으로 0과 1을 구분함
Generator 입장에서는 discriminator가 진짜 이미지를 구분하는지 못하는지 관심이 없음
그저 본인이 생성한 이미지가 얼마나 discriminator을 잘 속일 수 있는지가 중요함
즉, $D(G(z))$가 1이 되도록 하는 것이 중요함

먼저 $G$의 관점에서, $G$는 $V(D, G)$가 최소이길 원하고, $D$는 $V(D, G)$가 최대이길 원함
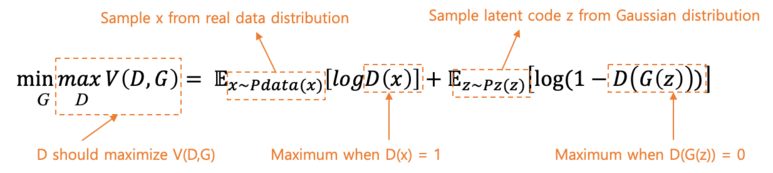
$V(D, G)$은 GAN의 loss 함수(objective 함수)이며, $D$의 목적은 해당 값이 최대가 되도록 하는 것임
경찰 $D$는 가짜 데이터에는 0을 출력하고, 진짜 데이터에는 1을 출력해야 함
진짜 데이터에 대해, $D(x) = 1$이 되어야 하며, 가짜 데이터에 대해, $D(G(z)) = 0$이 되도록하는 것이 목표임

정리하자면 $D$가 가장 원하는 상황은 위와 같음
즉, $log(D(x))$와 $D(G(z))$ 모두 0이 되는 것을 목표로 함
$z$는 랜덤하게 뿌려진 벡터인데, gaussian distribution 또는 uniform distribution을 따름


다음으로 $G$의 관점에서, $D$가 어떻게 하는지는 관심이 없고, $D(G(z)) = 1$이 되길 원함
$log(1 - 1) = log 0 = - \infty$ 이므로, 음의 무한대가 되는 방향으로 가는 것을 목표로 함
이제 StyleGAN도 공부해보고, 코드도 작성해봐야겠다!
'Run > Machine Learning' 카테고리의 다른 글
| [Machine Learning] CS231N #12 Visualizing and Understanding (1) | 2023.11.12 |
|---|---|
| [Machine Learning] CS231N #11 Detection and Segmentation (1) | 2023.10.30 |
| [Machine Learning] CS231N #10 Recurrent Neural Networks (2) | 2023.10.26 |
| [Machine Learning] CS231N #9 CNN Architectures (0) | 2023.10.26 |
| [Machine Learning] CS231N #7 Training Neural Networks 2 (0) | 2023.10.17 |