2023. 10. 30. 02:35ㆍRun/Machine Learning
Stanford University CS231n, Spring 2017
CS231n: Convolutional Neural Networks for Visual Recognition Spring 2017 http://cs231n.stanford.edu/
www.youtube.com

여태껏 다룬 Image Classification은 이미지를 input으로 받아 label을 output으로 냄
컴퓨터 비전 분야에는 Image Classification 말고도 여러 task가 있음
Semantic Segmentation

Semantic Segmentation은 이미지를 input으로 받고, 이미지의 모든 픽셀에 대해 카테고리를 판단하는 것임
하지만 오른쪽 예시처럼 두 cow를 서로 구분하지 않고 단지 cow로만 판단함

Semantic Segmentation을 수행하기 위해 Sliding Window 기법을 생각할 수 있음
여러 patch를 만들어서 수행하는 방식인데, 계산량이 너무 많기 때문에 절대 사용하지 않음

다음으로 Fully Convolutional 네트워크를 사용하는 방식임
모든 레이어를 거치고 난 후 마지막 convolutional 레이어는 C x H x W 의 tensor를 output으로 냄
(C: 모든 카테고리에 대한 점수 / C x H x W: 모든 픽셀에서의 모든 카테고리에 대한 점수)
모든 Conv 레이어에서 input과 동일한 spatial size를 유지해야 하고
모든 픽셀에 대한 카테고리의 점수를 계산해야 하기 때문에 계산량이 많음
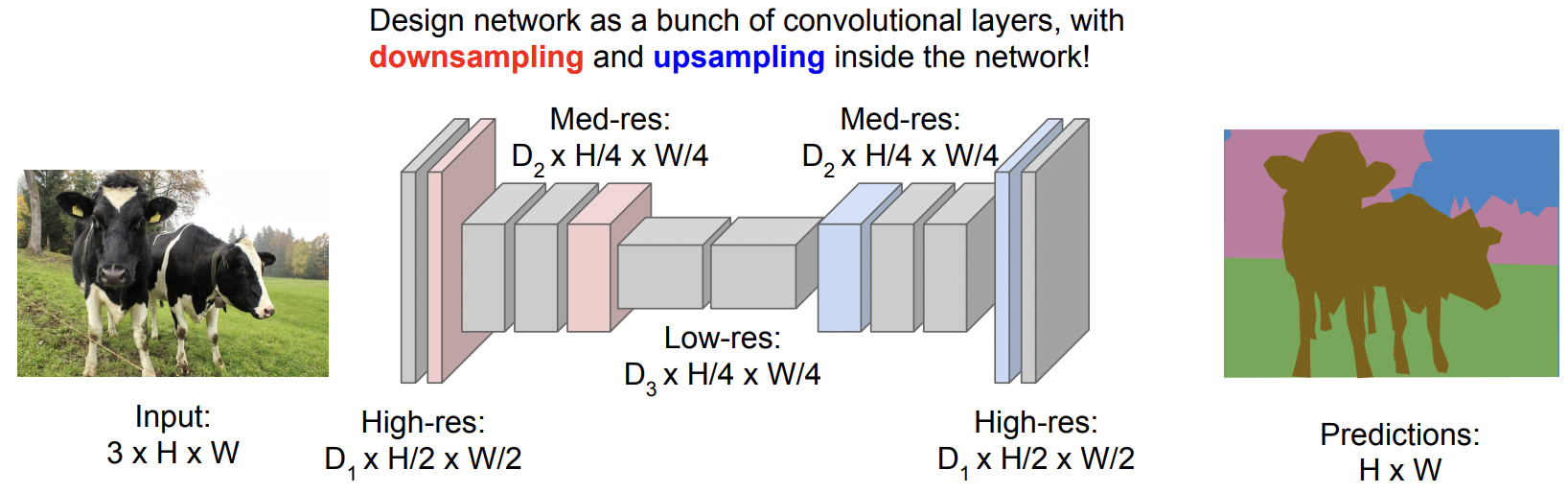
이에 대한 대안으로, downsampling을 했다가 다시 upsampling을 하는 방식이 고안됨
이렇게 하면 네트워크를 깊게 만들 수도 있고 중간에 크기를 줄일 수도 있으므로 좋음
Downsampling을 하는 방식에는 이전에서 다룬 pooling, strided convolution 등이 있음
그럼 Upsampling은 어떻게 할까?
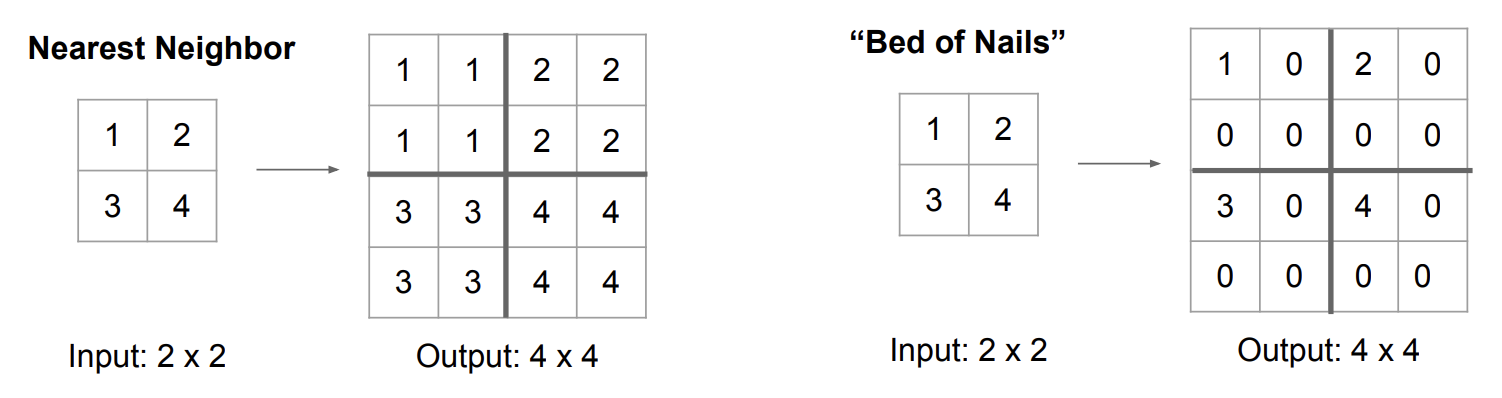
1. Unpooling
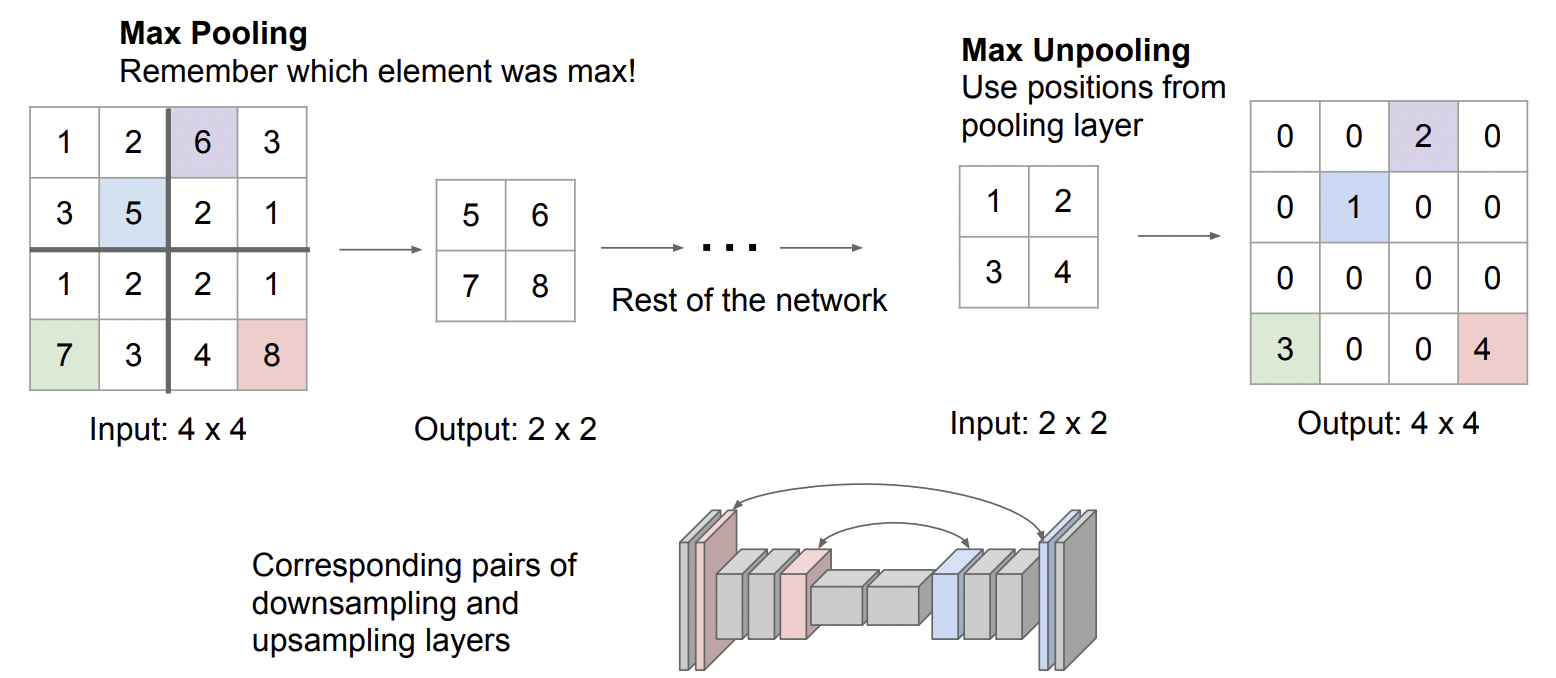
2. Max Unpooling
3. Transpose Convolution
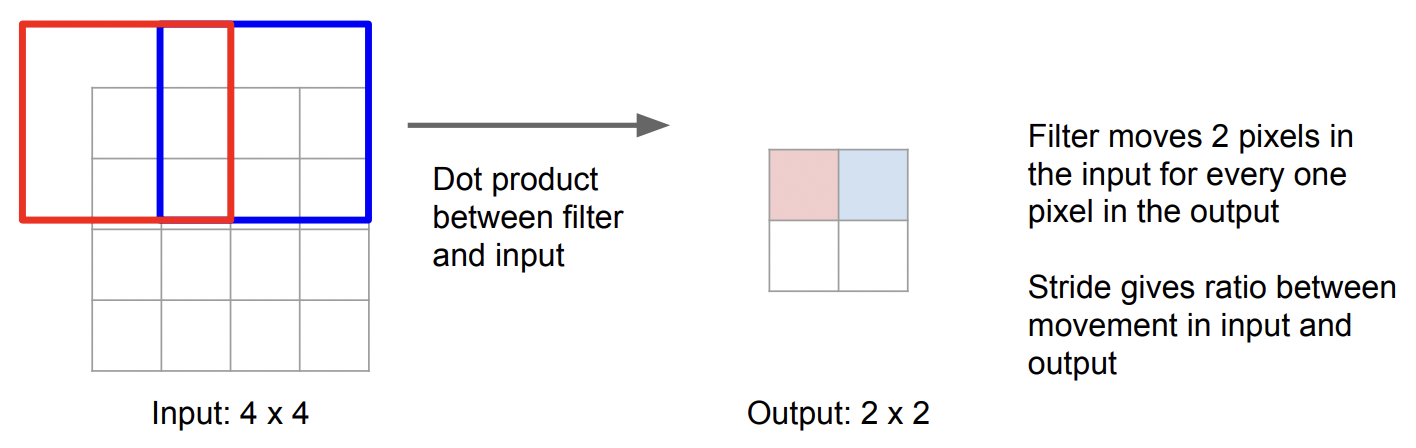
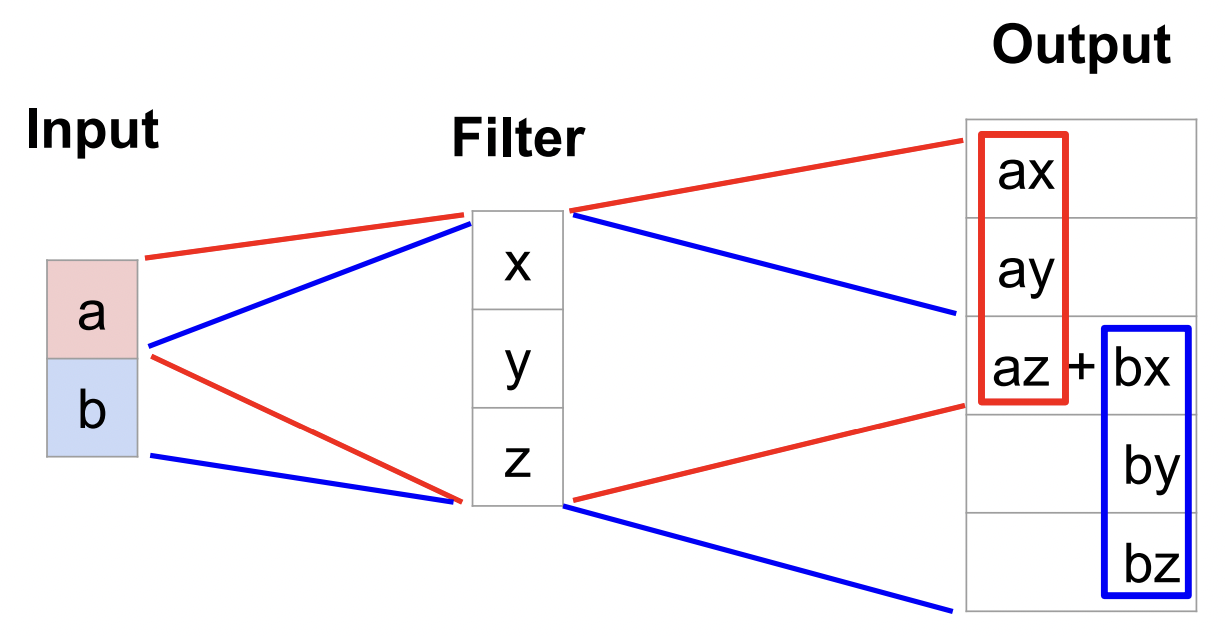
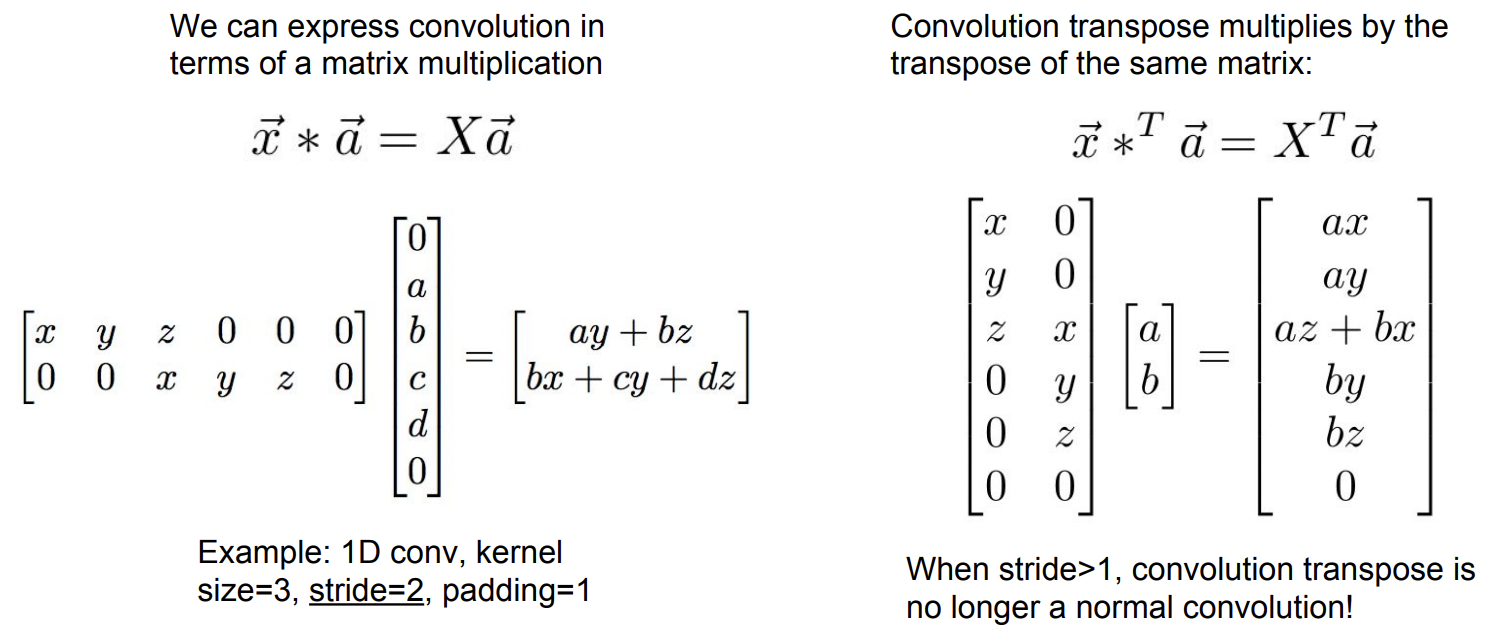
이 방식을 사용하면 학습이 가능함
Filter의 값을 곱해 계산함 (위 예시에서는 3 x 3 filter)
만약 겹치는 부분이 있을 경우, 해당 픽셀에 있는 값들을 모두 더하면 됨
Classification + Localization
고양이 사진을 input으로 넣으면 단순히 '고양이'라고 output을 내는 것이 아니라,
사진 속 어느 부분(bounding box)에 고양이가 있는지까지 인식하는 task임
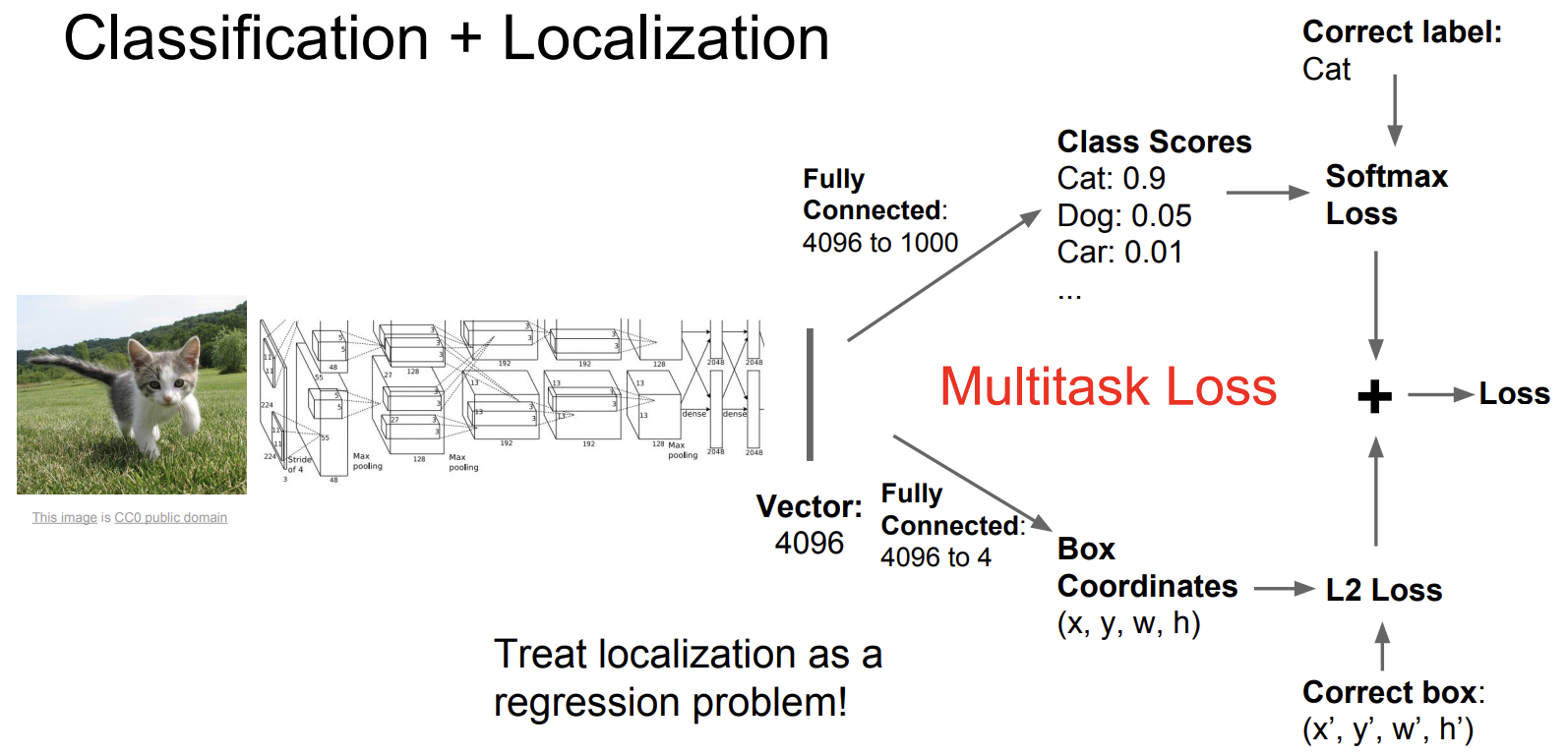
위를 예시로 설명하자면, 고양이 사진을 convolutional network(AlexNet)에 넣고
output으로 나온 이미지 vector을 FC layer에 넣어 최종 score을 계산함
기존과 다른 것은 또다른 FC layer에도 넣어 4개의 수(x, y, w, h)를 얻음
이들은 height, width, bounding box의 position을 나타냄
학습할 때는 두 개의 loss를 사용함
첫 번째는 score에 대한 Softmax loss이고, 두 번째는 예측한 bounding box에 대한 L2 loss임
이때 두 loss의 단위가 달라 gradient 계산이 되는지 의문이 들 수 있는데,
multitask loss이기 때문에 네트워크 weight의 각각의 미분값을 계산하므로 상관 없음\

이러한 방식으로 Human pose estimation에도 적용할 수 있음
Object Detection
한 장의 이미지에서 다수의 물체를 찾고, 그 물체가 어디에 있는지 알아내는 task임
Classification + Localization과 다른 점은 이미지마다 객체 수가 달라 미리 예측할 수 없다는 것임
크게 2-stage detector와 1-stage detector로 나눌 수 있는데,
classification과 localization을 단계별로 구분해서 하는 경우 전자, 한 번에 진행할 경우 후자임
Bounding box를 찾아내는 것은 classification이 아닌 regression임
Object detection을 하는 경우에는 여러 bounding box를 찾아내야 하므로, localization 외의 방법이 필요함
→ Region Proposal

Region proposal은 여러 개의 region 후보군에서 객체가 있을 만한 bounding box를 찾아내는 방식임
주변 픽셀 간의 유사도를 기준으로 segmentation을 만들고, 이를 기준으로 bounding box를 추론함
이는 딥러닝이 아니라 컴퓨터비전 기술인데 현재는 전부 딥러닝으로 수행하고, R-CNN은 잘 쓰이지 않음
R-CNN

Selective search algorithm으로 ROI를 추출한 후, CNN을 학습시키기 위해 input size를 맞춰주고,
CNN을 거친 다음 SVM을 통해 classification 과정을 거치고, linear regression을 통해 bounding box의 loss를 계산하고,
두 loss가 최소가 되는 방향으로 학습해나감
R-CNN은 초창기 모델이라 계산량이 많고, 느린 등 한계가 존재함
Fast R-CNN
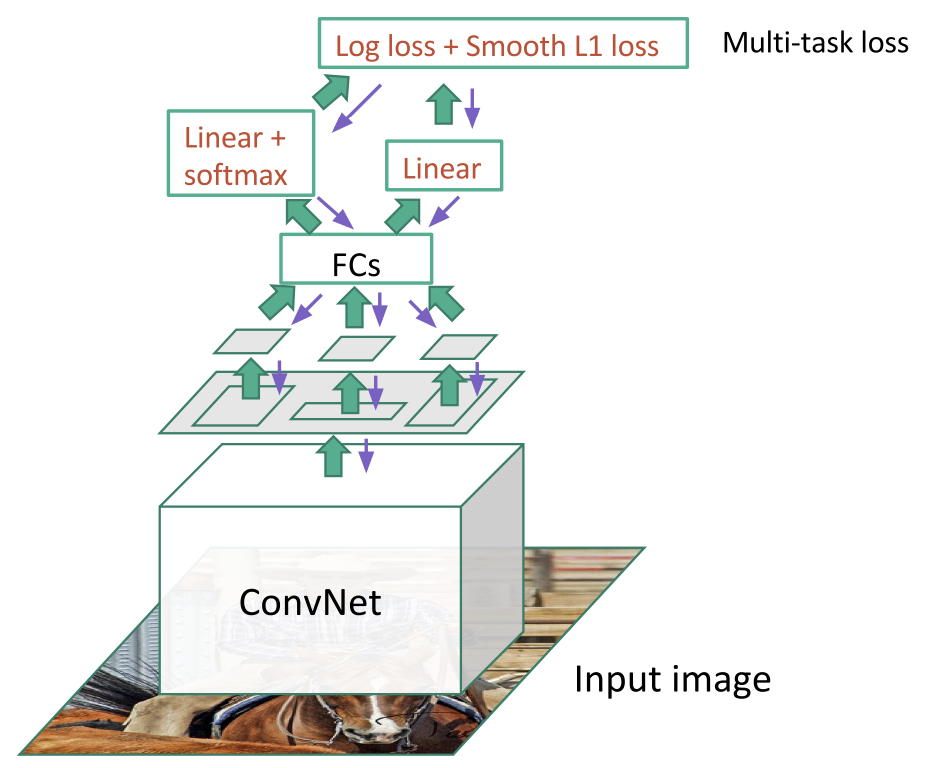
R-CNN에서 계산량이 많은 이유는 각각의 ROI에서 CNN 과정을 거쳤기 때문임
이에 Fast R-CNN에서는 이미지에 대해 딱 한 번의 CNN 과정을 거치고, feature map에서 region proposal을 찾음
이때 문제는 각 ROI가 다르기 때문에 일반적인 pooling으로는 input size가 통일되지 않는다는 것임
따라서 ROI pooling이라는 기법을 통해 feature map의 size를 통일시킴
FC layer를 통해 classification에 대한 loss 값과, bounding box에 대한 loss 값을 계산함
Faster R-CNN

Faster R-CNN에서는 region proposal도 딥러닝으로 수행함 (Region Proposal Network)
따라서 loss가 2개 더 추가되어 4개의 loss가 나옴
RPN에서 객체의 유무를 판단하고, RPN에서 bounding box의 좌표를 예측하고,
객체의 최종 분류 score을 반환하고, 최종 bounding box 좌표를 반환함
이를 multi task로 수행하여 매우 빨라짐
YOLO / SSD

YOLO(You Only Look Once), SSD(Single Shot Detection)은 region-based 방식이 아님
Classification과 localization을 하나의 네트워크에서 한 번에 진행함
Bounding box를 찾으며 confidence라는 변수를 통해 어느 class에 해당하는지도 예측함
YOLO와 SSD의 차이는 grid를 설정하는 방식임
Instance Segmentation
Mask R-CNN
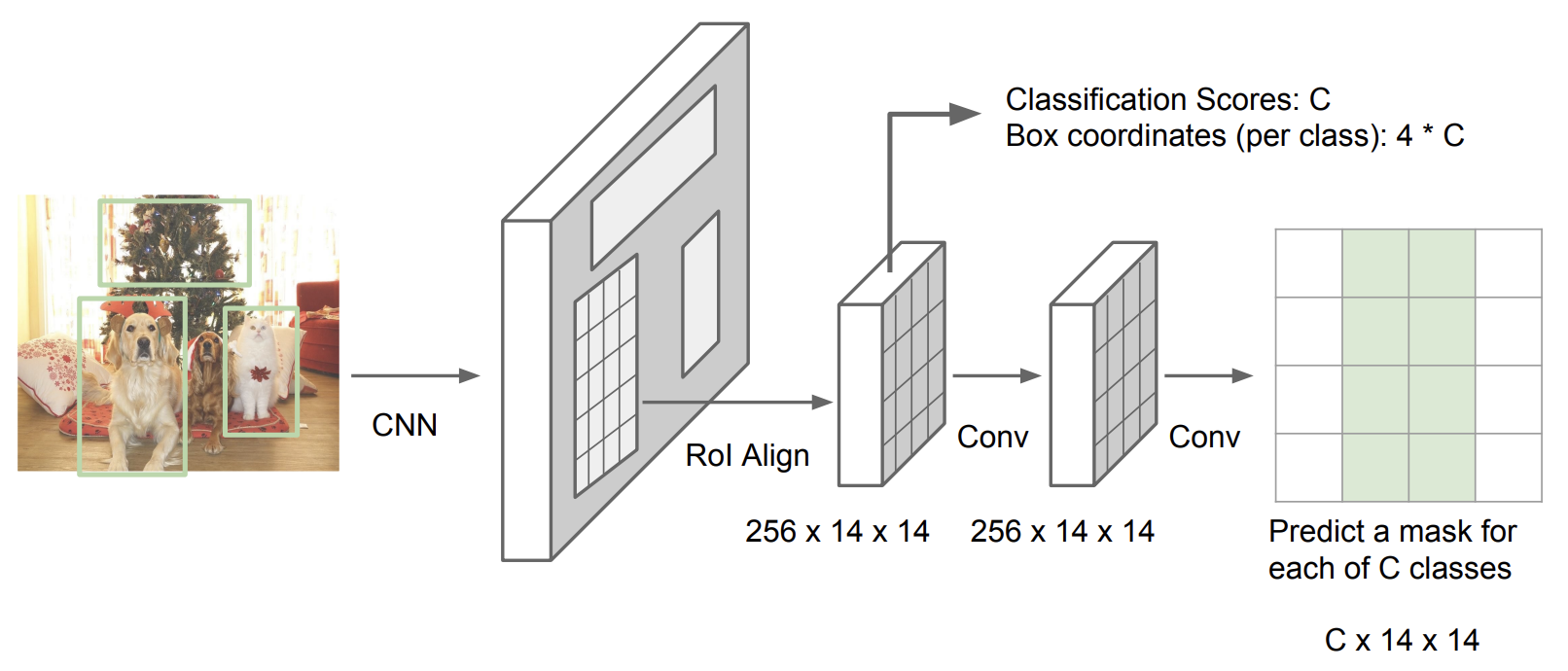
Semantic segmentation과 object detection을 합친 task임
'Run > Machine Learning' 카테고리의 다른 글
| [Machine Learning] AE, VAE, GAN (1) | 2023.11.22 |
|---|---|
| [Machine Learning] CS231N #12 Visualizing and Understanding (1) | 2023.11.12 |
| [Machine Learning] CS231N #10 Recurrent Neural Networks (2) | 2023.10.26 |
| [Machine Learning] CS231N #9 CNN Architectures (0) | 2023.10.26 |
| [Machine Learning] CS231N #7 Training Neural Networks 2 (0) | 2023.10.17 |